Язык маленьких детей лучше описывают лексико-специфичные грамматики, а не абстрактные

Как ребенок усваивает родной язык, никто до сих пор толком не знает. Теории, описывающие этот процесс, различаются тем, сколько абстрактных знаний они приписывают ребенку. Американо-германская группа когнитивистов показала, что грамматики, построенные на использовании конкретного лексического материала, лучше моделируют детскую речь, чем полностью абстрактные грамматики. Попутно они продемонстрировали, что с возрастом грамматика, существующая «в голове» у ребенка, становится менее индивидуальной; что в три года она устроена значительно сложнее, чем в два; и что в два года у детей уже есть некоторые представления о категории существительного, а в три года — о категории глагола.
Универсальная грамматика
Как ребенку удается овладеть языком — один из самых сложных вопросов когнитивной науки. Удивительно, во-первых, как быстро это происходит, во-вторых, как мало нужно ребенку внешней информации, чтобы практически полностью освоить всю систему языка.
Одна из гипотез, объясняющих наличие таких способностей, — это существование некой универсальной грамматики (УГ). УГ — это общий для всех языков набор правил, который человеку выучивать не нужно: владение им — врожденная способность.
Расцвет теорий, пытавшихся описать УГ, начался в 50-е годы XX века благодаря американскому лингвисту Ноаму Хомскому (Noam Chomsky). Хомский четко сформулировал гипотезу об УГ и предложил лингвистическую теорию, в рамках которой ее можно было бы описать. Эта теория — генеративная грамматика — оказала огромное влияние на всю современную лингвистику и надолго стала в ней доминирующей парадигмой.
Никому, однако, так и не удалось создать ни хорошее описание УГ, ни теорию, которая описывала бы, как ребенок на ее основании овладевает конкретным языком. Со временем популярность гипотезы об УГ снизилась, и даже сам Хомский от нее частично отказался.
Тем не менее влияние ранних идей Хомского было столь велико, что до сих пор немалая часть лингвистических работ посвящена полемике с этими идеями и их наследием.
Абстрактные категории
Пример такого наследия — представление, что языковая компетенция ребенка включает в себя много абстрактных правил и категорий. Языковая компетенция — это система правил, которая существует «в голове» у человека и позволяет ему говорить на данном языке.
В недавнем номере журнала PNAS Колин Баннард из Техасского университета в Остине совместно с Еленой Ливен и Майклом Томазелло (Michael Tomasello) из Института эволюционной антропологии Макса Планка в Лейпциге подвергают такое представление сомнению.
Опираясь на более ранние исследования Томазелло и Ливен, а также работы других авторов, исследователи выдвигают гипотезу, что владение языком у маленьких детей устроено совсем не так, как у взрослых. В частности, как раз абстрактные категории к нему плохо применимы.
Пример абстрактной категории — это части речи. Даже если взрослый носитель языка не знает терминов — скажем, глагол или существительное — он всё равно осознает, что слова ходить, делать, изучать ведут себя одним образом, а стол, стул, статья — другим. У слов из первого класса, бывают, например, разные времена, а у слов из второго — разные падежи.
Согласно гипотезе исследователей, у детей нет знания об этих двух классах, а есть лишь знания о поведении отдельных слов. На основании этих конкретных знаний они постепенно начинают делать обобщения, сначала частные, потом всё более и более широкие. Соответственно, и описывать их языковую компетенцию нужно с учетом этой особенности. Нельзя, например, вводить правило: «глагол всегда согласуется с существительным в лице и числе», так как некорректно оперировать категориями «глагол» и «существительное».
Баннард, Ливен и Томазелло придумали метод, позволяющий проверить эту гипотезу. Баннард осуществил проверку на большом корпусе детской речи.
Корпус данных и метод проверки
Корпус данных состоял из речи двух детей: Анни и Брайана. Исследователи записали на видео и транскрибировали по 30 часов речи каждого ребенка в возрасте двух лет и в возрасте трех лет (записи проводились в течение шести недель после соответствующего дня рождения).Транскрипции записей разделили на две части: тестовую (по два часа в два года и по часу в три года) и главную (всё остальное).
С примерами записи детской речи в формате CHAT, который она использовала, можно познакомиться на сайте Системы обмена данными детской речи (Child Language Data Exchange System, CHILDES). Ср. пример диалога с матерью девочки в возрасте 2 года 4 месяца.
Главная использовалась для того, чтобы автоматически построить формальную грамматику (о формальных грамматиках см. ниже), которая моделировала бы языковую компетенцию ребенка. С помощью специальных статистических методов компьютер выводил грамматику, порождающую все высказывания, содержащиеся в этом корпусе. Точнее, даже не одну грамматику, а целых две.
Одна — полностью абстрактная — была устроена согласно традиционным представлениям о языковой компетенции ребенка. В ней сначала порождается абстрактная синтаксическая структура предложения (ср. ниже описание КСГ-1), а затем в нее подставляются слова.
Вторая — лексико-специфичная — соответствовала представлениям исследователей. В ней порождаются не полностью абстрактные синтаксические структуры, а схемы, частично состоящие из конкретных слов, частично — из слотов (ячеек), которые заполняются другими словами или схемами.
Затем обе грамматики проверялись на тестовом корпусе. Оказалось, что лексико-специфичная грамматика описывает его более адекватно, чем полностью абстрактная.
Ниже приводится общее описание порождающих грамматик — формализма, на который опирались исследователи, затем — описание собственно грамматики Баннарда, а затем — подробное описание проведенных экспериментов и полученных результатов.
Порождающие грамматики
Контекстно-свободные грамматики
В общем случае грамматика языка X — это система правил, которая для любого предложения может определить, является ли данное предложение грамматически корректным в языке X или нет, и если да, то как оно устроено. Если эту систему можно формализовать и, например, научить ей компьютер, то говорят о формальной грамматике.
Самый известный класс формальных грамматик — это порождающие, или генеративные, грамматики, ведущие свое начало опять же от работ Хомского. (В принципе, «порождающая грамматика» и «генеративная грамматика» — это одно и тоже. Однако лингвистическую теорию Хомского по-русски обычно называют «генеративной грамматикой», а разновидность формальной грамматики вообще — «порождающей грамматикой».) Порождающая грамматика (ПГ) позволяет вывести все правильные предложения данного языка и только их. ПГ представляет собой набор правил порождения (продукций) вида X → Y (X переходит в Y). То, что стоит слева от стрелки, называется левой частью правила, то, что справа, соответственно, правой частью. Сверхзадачей Хомского, напомним, было объяснить, как ребенок умудряется хорошо говорить на языке (и понимать его), практически ему не обучаясь. ПГ как раз описывают, как носитель языка порождает предложения. Сторонники ПГ предполагают, что это адекватная модель настоящих когнитивных механизмов.
ПГ годятся не только для порождения, но и для анализа: как правило, используя специальные алгоритмы (см. CYK algorithm), можно быстро установить, порождается ли данное предложение в данной ПГ (то есть является оно грамматически корректным или нет).
Самый важный класс ПГ — контекстно-свободные грамматики (КСГ). В КСГ на левую часть правила никогда не влияет контекст, в котором она находится (строго говоря, в КСГ слева всегда стоит ровно один нетерминальный символ).
Рассмотрим простенькую грамматику КСГ-1, которая порождает синтаксические структуры некоторых предложений английского языка (слева от каждого формального правила приводится его лингвистический «смысл»):
| № | Правило | Лингвистическая интерпретация |
| 1 | S → NP VP | Предложение состоит из именной группы и глагольной группы |
| 2 | NP → ART N | Именная группа может состоять из артикля и существительного... |
| 3 | NP → N | ...или только существительного... |
| 4 | NP → ADJ N | ...или прилагательного и существительного... |
| 5 | NP → NP S* | ...или из именной группы и предложения... |
| 6 | NP → PRO | ...или из местоимения. |
| 7 | VP → V NP | Глагольная группа может состоять из глагола и именной группы... |
| 8 | VP → V VP | ...или глагола и глагольной группы. |
*Обратите внимание на правила 5 и 8: в них в явном виде выражено важное свойство ПГ — способность моделировать рекурсивные структуры языка.
Таблица 1. Пример контекстно-свободной грамматики. Правила из лекции (PDF, 175 Кб) Джеймса Аллена
На вход всегда подается символ S. Рассмотрим, что с ним дальше может произойти. Например:
S → NP VP (по правилу 1),
NP VP → PRO VP (по правилу 6),
PRO VP → PRO V NP (по правилу 7),
PRO V NP → PRO V ART N (по правилу 2).
Итого, мы породили цепочку PRO V ART N. Спрашивается, где же обещанное предложение английского языка? Представим, что наша КСГ дополнена словарем английского языка, и введем дополнительные правила типа: N можно заменить на любое существительное, V — на любой глагол и т. д. Тогда мы можем получить предложения типа I took an apple, He saw a table и т. п. Более того, если мы запомним, как именно мы породили это предложение, мы получим его синтаксическую структуру. Изобразим для наглядности порождение графически:
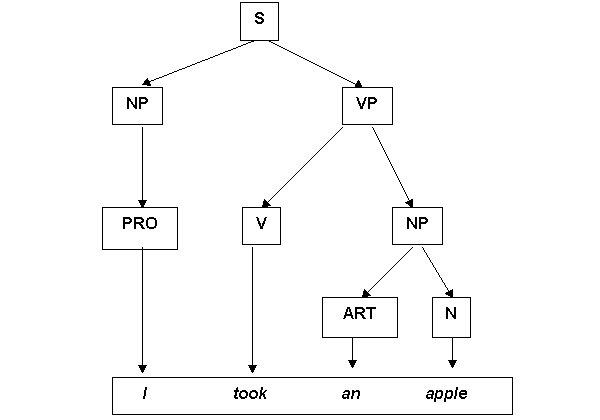
Мы нарисовали структуру, которая называется деревом непосредственных составляющих. Дерево состоит из узлов. Опыт показывает, что это неплохая модель синтаксической структуры предложения, по крайней мере с точки зрения лингвиста, который занят только описанием языка. Насколько хорошо она отражает то, что происходит в мозгу, вопрос значительно более сложный.
Очевидно, что в КСГ-1 символы ART, ADJ, N, PRO и V являются терминальными: они не могут стоять в левой части правил. Любой конечный продукт КСГ-1 будет последовательностью этих символов. S, NP и VP являются нетерминальными символами: ни в какой итоговой порожденной последовательности их не будет. Это логично: терминальные символы — это обозначения частей речи, которые будут заменены конкретными словами, а нетерминальные — это более крупные синтаксические группы, которые потом обязательно распадутся на неделимые единицы.
Вероятностные контекстно-свободные грамматики
Рассмотрим, может ли КСГ-1 породить предложение I hate annoying neighbors. Может, и даже двумя способами. Этому предложению могут быть приписаны две разные синтаксические структуры: «Я ненавижу мешать соседям» и «Я ненавижу соседей, которые мешают (мне)».
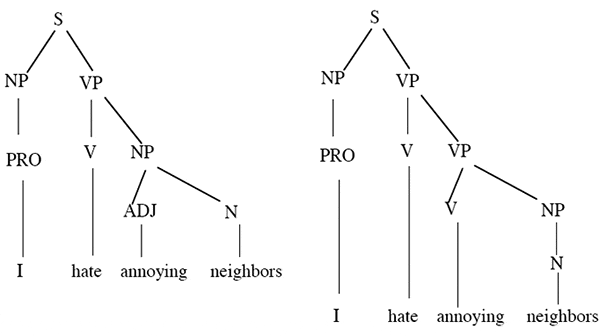
Возникает вопрос: нельзя ли определить, какая из этих структур более вероятна? В рамках обычной КСГ — нельзя. Для этого были созданы вероятностные (стохастические, пробабилистические) контекстно-свободные грамматики (ВКСГ).
В простейшей ВКСГ каждому правилу соответствует вероятность, с которой оно может быть реализовано (реализации всех правил считаются независимыми событиями).
Очевидно, например, что в КСГ-1 правило 1 реализуется с вероятностью 1 (S всегда переходит в NP VP). А вот чтобы приписать вероятность правилам 7 и 8, нужно знать, во что чаще переходит глагольная группа — в глагол и глагольную группу или глагол и именную группу. Самый надежный способ выяснить это — взять большой корпус предложений, которые могут быть порождены в этой грамматике, построить для каждого предложения синтаксическую структуру вручную, рассчитать частоту каждого перехода и принять ее за вероятность. Проведем подобный расчет на мини-корпусе из наших трех предложений (будем считать второе предложение за два омонимичных). Переход VP → V NP встречается три раза, а переход VP → V VP — один раз. Итого вероятность реализации правила 7 — 0,75, а правила 8 — 0,25.
Читатель может сам рассчитать вероятности для остальных правил и определить, какая структура второго предложения вероятней (поскольку мы считаем реализации правил независимыми событиями, найти вероятность порождения структуры можно простым перемножением вероятностей правил). Можно не ограничиваться вероятностями абстрактных правил, а принять во внимание и вероятности правил лексического заполнения, например: V → hate, V → annoying, ADJ → annoying и т. п.
Для настоящего анализа языков применяются значительно более изощренные КСГ и ВКСГ. В КСГ-1, например, никак не отражена необходимость согласовывать подлежащее и сказуемое, так что предложение типа I takes an apple она тоже признает правильным.
Именно ВКСГ легли в основу формализма, который использовал в своей работе Баннард.
Модель Баннарда
Исследователи придерживаются гипотезы, что дети сначала выучивают очень конкретные конструкции, привязанные к конкретным словам. Постепенно (после двух лет) эти конструкции становятся более абстрактными. Такой подход называется usage-based, что можно перевести как ориентированный на употребление, а в данном случае как лексико-ориентированный. В рамках этого подхода конкретные слова, устойчивые выражения, а также более абстрактные конструкции рассматриваются как знаки.
В своей модели Баннард различает два типа знаков. Первый — конкретные знаки: слова (drink), высказывания (I want a drink) или части высказываний (want a drink). Второй — схемы — состоит из конкретных знаков и слотов — пустых мест, куда можно вставлять другие знаки (обоих типов). В схеме всегда содержатся конкретные слова.
Похожие знаки можно объединять в группы, примерно соответствующие базовым семантическим категориям. При порождении каждому узлу приписывается какая-то категория, и заполнять его могут знаки только этой категории.
На рис. 3 показано, как, выделив две категории, можно породить и проанализировать фразу The man wants a chocolate biscuit с использованием схем (справа) и без него (слева).
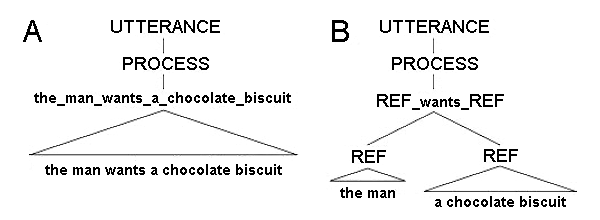
В категорию REF (от слова «референт») могут попадать только знаки, называющие объект (именные группы, существительные, местоимения и пр.), в категорию PROCESS — знаки, называющие процесс или действие (глаголы, глагольные группы). Категория UTTERANCE («высказывание») вводится для технических целей и является начальным символом для любого порождения.
Можно провести следующие приблизительные аналогии между грамматикой Баннарда и КСГ-1. Схемы подобны нетерминальным символам: они обязательно будут дополняться чем-то еще. Понятие категорий в КСГ-1 в явном виде не представлено, но очевидно, что в категорию REF попали бы знаки NP, N и PRO, а в категорию PROCESS — V и VP. Конкретные знаки подобны терминальным символам, но существенная разница в том, что у Баннарда конкретные знаки — это конкретный лексический материал, а в КСГ-1 это опять же абстрактные символы. На конкретные слова они будут заменяться лишь на конечном этапе, уже после порождения синтаксической структуры.
В этом и заключается главное отличие такого формализма от обычной КСГ: у Баннарда в правой части правил всегда имеются конкретные слова (впрочем, судя по рисунку, к порождению первого узла из служебной категории UTTERANCE это утверждение авторов не относится). Это дает авторам возможность называть свои правила лексико-специфичными, противопоставлять их абстрактным правилам и в конце концов приходить к своим главным выводам.
Работа модели
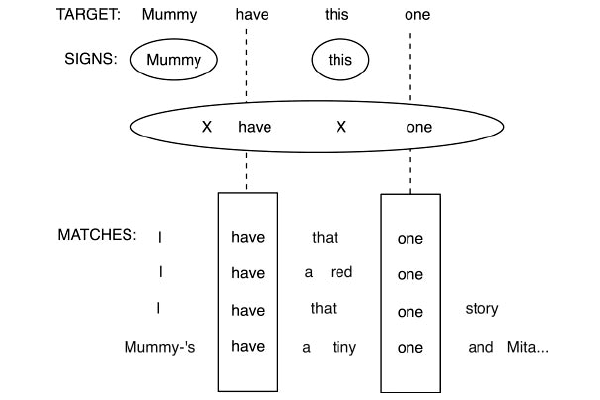
Грамматика Баннарда создается следующим образом. Для каждого высказывания в главной части корпуса ищутся все прочие высказывания, которые имеют хотя бы одно общее слово с данным. Все найденные высказывания выравниваются (см. рисунок 4.), после чего извлекаются все возможные схемы и конкретные знаки. В данном случае будут извлечены схема X have X one и конкретные знаки Mummy и this. Процесс выравнивая и извлечения повторяется для всех подстрок данного высказывания, которые состоят более чем из одного слова (в данном случае Mummy have, Mummy have this, have this, have this one и this one) — и так далее.
Получив все возможные знаки, необходимо найти лексико-специфичные ВКСГ, которые, опираясь на эти знаки, порождали бы все имеющиеся в корпусе высказывания. Это делается автоматически, методом байесовского неконтролируемого вывода грамматики (см. статьи: M. Johnson et al., 2007. Bayesian inference for PCFGs via Markov Chain Monte Carlo, PDF, 106 Кб; J. Finkel et al., 2007. The Infinite Tree, PDF, 280 Кб; P. Liang et al., 2007. The Infinite PCFG using Hierarchical Dirichlet Processes, PDF, 262 Кб).
Ни категории, ни правила порождения заранее не задаются, всё это программа выводит сама, подбирая оптимальную грамматику (точнее, не одну правильную, а диапазон наиболее подходящих грамматик). Единственное, что задается, — это предпочтение экономным грамматикам: таким, в которых меньше категорий и знаков. В итоге полученная грамматика полностью моделирует порождение всех высказываний в корпусе.
Абстрактная грамматика строится аналогичным образом: программа автоматически делит слова на категории и выводит правила порождения (X → Y). Количество категорий и правил при этом также заранее не задается.
Таким образом, исследователи в итоге получили по четыре абстрактных и по четыре лексико-специфичных грамматики (Брайан-2, Анни-2, Брайан-3, Анни-3), а также четыре корпуса, на которых их можно было протестировать.
Эксперимент 1: полнота анализа и мера удивления
Полнота
Лексико-специфичная грамматика Брайан-2 (полученная для корпуса высказываний Брайана в возрасте двух лет) состояла из 802 знаков и трех категорий, Анни-2 — из 1898 знаков и четырех категорий, Брайан-3 — из 5343 знаков и шести категорий, Анни-3 — из 5385 знаков и шести категорий. Разница неудивительна: в два года Анни говорила значительно лучше, чем Брайан. Согласно опроснику МакАртура (MacArthur-Bates Communicative Development Inventories), она опережала в языковом развитии 75% своих сверстников, тогда как Брайан — лишь 25%.
Видимо, с возрастом грамматики становятся менее индивидуальными, и различия сглаживаются.
Исследователи проверили, насколько хорошо эти грамматики позволяют проанализировать соответствующие тестовые корпуса. Основным показателем служила полнота, то есть доля успешно проанализированных высказываний.
Рассмотрим, что такое полнота, на примере КСГ-1. Некоторые предложения она породить может (например, I took an apple), некоторые — нет (например, I am reading between the lines). Таким образом, корпус из двух предложений I took an apple и I hate annoying neighbors КСГ-1 сможет проанализировать с полнотой 100%, а корпус из двух предложений I took an apple и I am reading between the lines — с полнотой 50%.
Результаты приведены на рис. 5.
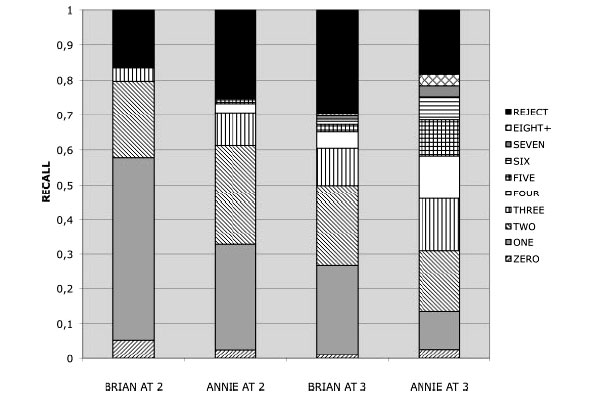
По оси ординат отложена полнота. Она достаточно высока во всех четырех случаях: 84%, 75%, 70% и 81% соответственно.
На диаграмме указан еще один интересный параметр — количество операций вставки, необходимое для правильного анализа высказывания. Вставка — это подстановка знака (конкретного или схемы) в слот какой-либо схемы (см. выше описание модели Баннарда), то есть просто заполнение слота в схеме. В самом низу каждого столбика указана доля высказываний, для анализа которых не нужно производить ни одной вставки (то есть все эти высказывания хранятся в грамматике в виде конкретного знака). Выше — доля тех, для анализа которых нужна одна вставка. Видно, что 58% высказываний Брайана в возрасте двух лет могут быть проанализированы с помощью не более чем одной вставки (иначе говоря, устроены с точки зрения грамматики очень примитивно). Двух вставок хватает для 80% высказываний, и лишь одно высказывание требует четырех вставок. У Анни в два года грамматика менее примитивна: с помощью не более чем одной вставки можно проанализировать лишь 32%, но двух вставок хватает уже для 61%.
В три года грамматики становятся гораздо сложнее. У Брайана не более чем одной вставки хватает для 26% высказываний, а 10% требуют не менее четырех вставок. У Анни соответствующие доли равны 13% и 36% (то есть она по-прежнему опережает Брайана во владении речью). Авторы называют характеристику языковой деятельности детей, которую можно оценить таким образом, продуктивностью и заключают, что к трем годам она существенно возрастает.
Мера удивления
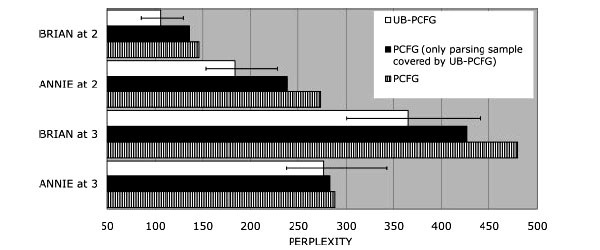
Исследователи также проверили, насколько хорошо полученные модели предсказывают тестовые данные. В качестве показателя они выбрали перплексивность (perplexity) — меру того, насколько хорошо распределение вероятностей событий (слов и высказываний) совпадает с распределением событий в реальных данных, иными словами — меру того, насколько модель «удивлена» реальными данными. Чем ниже перплексивность, тем выше вероятность порождения данного корпуса текстов в данной грамматике и, соответственно, тем адекватнее модель.
Перплексивность вычислить можно, но как оценить полученные значения? Для сравнения исследователи используют полностью абстрактные ВКСГ, выведенные на тех же данных. Эти грамматики похожи на нашу КСГ-1: слова в них содержатся только в словаре, и в правилах порождения не фигурируют. На рис. 6 видно, что у лексико-специфичных ВКСГ перплексивность ниже.
Эксперимент 2: кросс-предсказуемость
Насколько полученные грамматики привязаны к особенностям данного ребенка или данного возраста? Чтобы найти ответ на этот вопрос, исследователи применили каждую из четырех грамматик к каждому из четырех тестовых корпусов. Результаты (полнота и перплексивность) приведены в таблице 2:
| Грамматика Брайан-2 | Грамматика Анни-2 | Грамматика Брайан-3 | Грамматика Анни-3 | |
| Корпус Брайан-2 | 84% (105,4) | 36% (636,3) | 46% (1076) | 34% (1486,2) |
| Корпус Анни-2 | 15% (381,9) | 75% (184,1) | 71% (317,6) | 81% (425,9) |
| Корпус Брайан-3 | 8% (455,7) | 42% (361,5) | 70% (364,6) | 63% (363,7) |
| Корпус Анни-3 | 3% (489,5) | 29% (526,4) | 59% (575,8) | 81% (276,5) |
Таблица 2. Полнота и перплексивность при применении разных грамматик к разным тестовым корпусам (из обсуждаемой статьи в PNAS)
Видно, что грамматики, полученные в возрасте двух лет, плохо справляются с корпусами, собранными в возрасте трех лет. В случае Брайана это особенно сильно (видимо, относительное развитие за третий год жизни у него было больше, чем у Анни). Но гораздо интереснее, что и грамматики, полученные в три года, плохо справляются с корпусами, собранными в два года. Правда, полнота при применении грамматики Анни-3 к корпусу Анни-2 выше, чем у грамматики Анни-2, но зато гораздо выше и перплексивность. Грамматика же Брайан-3 справляется с корпусом Брайан-2 гораздо хуже, чем грамматика Брайан-2, по обоим параметрам. Это позволяет исключить опасение, что грамматики чрезмерно «мягкие», то есть разрешают слишком много высказываний.
Что касается различий между детьми, то видно, что грамматики Брайана хуже справляются с данными Анни, чем грамматики Анни, а грамматики Анни хуже справляются с данными Брайана, чем грамматики Брайана. Существенно, однако, что в три года разница меньше, чем в два. Это подтверждает тезис лексико-ориентированного подхода: вначале грамматики очень индивидуальны, постепенно они становятся всё более и более похожими на общепринятые.
Эксперимент 3: добавление категорий
Лексико-ориентированный подход предполагает, что дети овладевают абстрактными категориями постепенно. В более ранних работах Томазелло доказывал, что в 23 месяца дети уже владеют категорией существительного, а в 25 еще не владеют категорией глагола.
Исследователи рассмотрели, что происходит, если автоматический вывод грамматики немного «подтолкнуть», заранее приписав словам некоторые грамматические категории. Сначала они добавляли категории имени нарицательного (N) и имени собственного (PropN), то есть «помечали» имена существительные; затем добавили и категорию глагола (V). Для этого использовалась ручная разметка корпусов, где каждому слову была приписана его часть речи.
Результаты представлены на рис. 7.
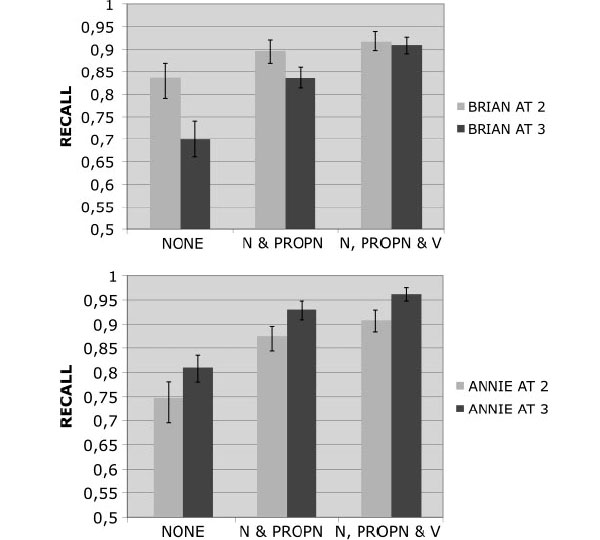
В два года у обоих детей добавление категорий имен существенно увеличивает полноту: 6% для Брайана, 13% для Анни. Добавление категории глагола увеличивает полноту лишь немного: еще 2% для Брайана (причем полнота лежит в пределах возможной ошибки для предыдущего результата, когда заданы только категории имен); еще 3% для Анни (здесь полнота выходит за пределы возможной ошибки).
В три года у Брайана добавление категорий имен улучшает полноту на 14%, а глагола — еще на 7%. Для Анни результаты не меняются: снова 13% и еще 3%.
Эти результаты в целом соответствуют предположениям авторов: в два года у детей уже есть какое-то общее представление о категориях имен, а в три — о категории глагола. Не очень хорошо вписывается лишь тот факт, что у Анни в три года добавление категории глагола не произвело почти никакого эффекта. Авторы предполагают, что она овладела всеми тремя категориями уже в два года, и к трем существенных изменений не произошло.
В любом случае исследователи отмечают, что освоение категорий происходит очень постепенно, поэтому брать и вводить сразу полностью категории имен и категорию глагола — достаточно грубый метод. Он позволяет с уверенностью утверждать лишь одно: в два года категории имен у детей уже не полностью привязаны к конкретным словам. В три года то же самое можно сказать и про категорию глагола.
Заключение
Авторам удалось подтвердить свою гипотезу: лексико-специфичные грамматики работают лучше абстрактных. Причем они, возможно, не просто лучше работают, а лучше отражают когнитивную реальность. Кроме того, эти грамматики позволяют описать, как развивается и усложняется языковая компетенция ребенка (за третий год жизни — очень сильно).
Исследование подтвердило другие тезисы лексико-ориентированного подхода. Во-первых, с возрастом грамматики становятся всё менее индивидуальными и более взаимозаменяемыми. Во-вторых, освоение грамматических категорий происходит постепенно (существительного — раньше, глагола — позже).
Интуитивно все эти выводы кажутся вполне правдоподобными. Отказ от чрезмерно абстрактных моделей действительно позволяет лучше описать речь детей.
Жаль, однако, что лексико-специфичные грамматики сравниваются с абстрактными только по перплексивности, но не по полноте, а с грамматиками, включающими категории имени и глагола, — только по полноте, но не по перплексивности. Кроме того, возникает стандартный для подобных исследований вопрос: можно ли делать глобальный вывод на основании данных, полученные только для одного языка (английского) и для одного типа грамматик (ВКСГ)?
Авторы перечисляют и другие возможные ограничения на свои выводы. Во-первых, они рассматривали лишь маленькую выборку (около 5%) из всех тех высказываний, которые дети породили за год. Во-вторых, они изучали только порождение высказываний — существует мнение, что дети на самом деле знают грамматику лучше, чем показывает их продуктивность, просто часть высказываний не могут породить.
Поэтому свой окончательный вывод Баннард, Ливен и Томазелло формулируют так: им удалось продемонстрировать, что лексико-специфичный подход к описанию речи детей, начинающих осваивать язык, хорошо выдерживает стандартные критерии оценки.
Источник: Colin Bannard, Elena Lieven, Michael Tomasello. Modeling children's early grammatical knowledge // Proceedings of the National Academy of Sciences. 13 October 2009. V. 106. No. 41. P. 17284–17289.
Александр Бердичевский
-
Почему-то при чтении статьи подумалось о том, что для понимания что такое язык нужно изучать развитие глухих с рождения детей. Тут абсолютно чистый эксперимент без привязок к особенностям конкретных языков.
-
Я бы сказал, что это мнение ошибочно. Механизм, ответственный за языковое (вербальное) описание мира один и тот же, независимо от того, как именно осуществляется вербализация (т.е. сопоставление ярлыков наблюдаемым действиям и состояниям). Т.е. не важно, какой именно ярлык -- звуковой или моторный -- ставится в соответствие миру, механизм обучения языку будет одним и тем же.
С другой стороны, т.к. в случае глухого (фактически -- глухонемого) ребенка участие взрослых в формировании вербального описания будет намного активнее, здесь исследовать процесс САМОобучения языку будет намного сложнее.-
[b]С другой стороны, т.к. в случае глухого (фактически -- глухонемого) ребенка участие взрослых в формировании вербального описания будет намного активнее, здесь исследовать процесс САМОобучения языку будет намного сложнее.[/b]
Идея в том, что если родители нормальны, и не знают языка глухонемых, то можно будет проследить процесс САМОЗАРОЖДЕНИЯ языка. А ведь это и интересно в конечном итоге. Как у людей возник язык?-
ТАК получить ответ на вопрос о самозарождении языка, увы, не получится. Просто будет еще один "ребенок джунглей". Что из этого получится -- хорошо известно: дети, которые воспитывались животными, собственного языка (вербальной системы) не имеют.
Если уж ставить подобный эксперимент, то надо забросить достаточно большую популяцию новорожденных в джунгли, обеспечить их выживаемость и посмотреть, что с ними произойдет за 1-5-10 тысяч лет. Мысленно такой эксперимент не проделать, а в реальной жизни ни один нормальный человек на такое не пойдет.
Так что единственный путь -- это научиться различать и понимать процессы, происходящие в сознании, как это умеют, например, крутые йоги или буддисты. Тогда можно будет построить модель, адекватную РЕАЛЬНЫМ процессам, и разработать методы ее проверки. А те игры с моделями, в которые играют лингвисты и психологи, ровыным счетом ничего не дают для понимания РЕАЛЬНЫХ ПРОЦЕССОВ, происходящих в сознании человека и ребенка, осваивающего язык, в частности.
-
-


-
И маленькие дети, и животные понимают не слова (абстрактные ярлыки), а состояния. В принципе, это можно назвать хорошо развитой эмпатией, граничащей с зачатками телепатии. Именно этот механизм и лежит в основе "автоматического" освоения структуры языка: ребенок фокусирует свое внимание на говорящем взрослом, непосредственно воспринимает его состояние (сумму ощущений), и параллельно запоминает абстрактные ярлыки (звуки или телесные ощущения, если ребенок глухонемой), соответствующие состояниям, о которых говорит взрослый.
Например, если взрослый говорит "Посмотри на птичку!", он не только показывает на нее рукой, но и показывает состояние "интереса" или "фокуса внимания", привязанного к птичке. Ребенок, считав (ощутив) это состояние, фокусируется на птичке, и одновременно запоминает жест взрослого и его слова. При накоплении достаточного количества повторений ситуации "ощущение-действие-слово" ребенок усваивает их взаимосвязи и, когда у него возникают аналогичные состояния (например, желание привлечь внимание к чему-то), он начинает использовать аналогичные слова, ожидая, что они приведут к желательному эффекту.
Животные действуют по тому же принципу, но их объем памяти гораздо меньше, а возможность артикуляции практически никакая по сравнению с человеком. Поэтому маленькие дети, у которых механизм эмпатического восприятия еще достаточно активен, могут понимать животных гораздо лучше, чем взрослые, у которых этот механизм вытеснен вербальной (абстрактной) коммуникацией.
Очевидно, что, исключая из рассмотрения механизмы непосредственного считывания (передачи) состояния (т.к. они не вписываются в современную научную парадигму), психологи и лингвисты существенно искажают описание реального процесса и, соответственно, порождаемые ими модели как функционирования языка, так и механизмов его усвоения не соответствуют реальности.-
1."...взаимосвязи...", "...аналогичные ситуации...", "_а_н_а_л_о_г_и_ч_н_ы_е_ слова". Чем это отличается от того, что в статье? Что потеряли/исказили исследователи?
2.К чему это "непосредственное считывание"? Разве некоторые артисты не демонстрируют чудеса опосредованного съема информации?-
1. Авторы статьи, как добросовестные ученые, не пытались говорить о механизмах сознания, а лишь обсуждали преимущества одной формальной модели перед другой. Здесь они находятся на вполне твердой почве -- как модель вероятностной контекстно-свободной грамматики, так и модель Баннарда в равной мере могут быть применены как к человеку (ребенку), так и к роботу. Более того, авторы, фактически, построили двух роботов, "познающих" мир в соответствии с этими моделями. В конце концов подтвердилось предположение, что робот, использующий модель лексико-ориентированной грамматики, работает лучше, т.е. он может породить больше высказываний, которые соответствуют записанным высказываниям ребенка. Вполне возможно, что более сложный робот с более сложной лексико-ориентированной грамматикой сможет порождать даже более-менее осмысленные тексты.
Приблизились ли мы после этого к пониманию того, как новорожденный порождает эту лексико-ориентированную грамматику? Ничуть. Можно ли хотя бы в принципе из этой модели понять, посредством каких физических и физиологических механизмов эта грамматика порождается, даже если мы полностью убедимся, что детская речь действительно может быть описана лексико-ориентированной грамматикой? Нет, нельзя. Именно это я и имел в виду, когда говорил о неполноте моделей, используемых, в частности, когнитивистами. Они описывают только ЧАСТЬ реальности, соответствующую уже работающему механизму речи, но ничего не говорят о ВОЗНИКНОВЕНИИ этого механизма.
2. "Непосредственное считывание" относится как раз к этапу ПЕРВИЧНОГО формирования механизма речи. Насколько я знаю, дети осваивают язык к двум годам независимо от того, общаются (сюсюкают) ли с ними взрослые, или же не обращают на них специального внимания. Т.е. механизм формирования речи -- активный, действующий "со стороны ребенка". Тезис о "непосредственном считывании" утверждает, что, например, если новорожденного поместить в комнату, где будет телевизор и радиоприемник, через которые будут транслироваться те же разговоры, что и в реальной семье (т.е. будет моделироваться ситуация освоения речи без специального обучения), но не будет живых людей, то ребенок к двум годам так и останется немым, если с ним не будет специально заниматься робот-нянька. С другой стороны, я могу предположить, что ребенок, окруженный "общающимися" андроидами, которые моделируют общение людей и их реакции на действия ребенка, в принципе, может освоить речь, но, лишенный возможности "непосредственного считывания" состояний, сделает это либо позже, либо хуже.
Нетрудно понять, что "грамматическая модель" в принципе не может дать никакого прогноза для подобных ситуаций. Поэтому я и говорю, что она неполна.
3. Считывание идеомоторных реакций некоторыми артистами, в принципе, имеет несколько другую природу и уж точно не базируется на бессознательно-генетических программах. Хотя кое-кто из таких артистов вполне может пользоваться и "непосредственным считыванием". Но это -- уже совсем другое дело.-
Почему самолеты летают, но крыльями не машут?
Поймите, ценность подхода лингвистов заключается в том, что они пытаются вывести общие законы (по сути мат. модели) формирования и осознания речи. При этом совершенно не важно, какие именно **биохимические** процессы происходят в мозгу у детей. И эффективные модели будут означать появление, например, вменяемых систем автоматического перевода с одного языка на другой. Или интеллектуальных речевых интерфейсов (навскидку тоже развитие Google Voice Search для iPhone/Android). Я, например, не владею китайским. И вряд ли когда либо выучу сильно больше той дюжины слов и выражений что уже знаю. Но интересной информации доступной только на китайском все больше и больше. И хочу/не хочу но пользоваться компьютерным переводом приходиться.
А самолеты... Самолеты появились после того, как у человечества возникло понимание основ аэродинамики. А знание конкретно внутреннего строения птиц и механизма их полета при этом было малополезно.-
"Поймите, ценность подхода лингвистов заключается в том, что они пытаются вывести общие законы (по сути мат. модели) формирования и осознания речи."
Если говорить ТОЛЬКО о лингвистах и лингвистике, как науке об интерпретации знаковых описаний, то тут никаких проблем или претензий не будет. В конце концов, здесь важен прежде всего практический результат (расшифровка текста на неизвестном языке или создание системы компьютерного перевода). И, опять же, в конечном счете неважно, был ли получен этот результат на основе абстрактной грамматики или лексико-ориентированной.
В этом контексте учет реальных психофизиологических механизмов интерпретации/генерации текстов, в общем, может помочь строить более эффективные программы (т.е. работающие быстрее, занимающие меньший объем или порождающие более толковые тексты). С другой стороны, вполне может оказаться, что от всей психофизиологии останется всего несколько десятков правил, умещающихся на одном-двух листках.
Но я говорю не об этой ситуации, а о познании механизмов функционирования сознания и психики. Там лингвистические формальные модели будут либо сильно ограниченными, либо вообще неадекватными, даже если они и будут весьма эффективны в сфере компьютерного перевода. Ведь даже научившись делать сверхзвуковые самолеты, мы все равно не узнаем больше о том, как именно управляют своим полетом птицы или насекомые. Ведь самолеты крыльями не машут...
-
-
-
-
-
И те и другие используют слова плюс устойчивые выражения. Слова это те же глаголы, существительные, прилагательные. А как конкретно записываются слова, ограниченным набором символов или группой пиктограмм не имеет значения.
Единственное, на вскидку, сильное отличие CJK от остальных языков, это сложность разбиения текста на слова. Это прежде всего важно для индексации текстов для поиска или в случае спеллчекеров. Лидирующие поисковые системы используют продвинутые системы с алгоритмами грамматического анализа. А алгоритмы реализованные в продуктах с открытым кодом срабатывают чуть больше чем с 95% вероятностью. Но это больше компьютерная проблема, мало влияющая на ментальность носителей языка. -
Прежде всего, придирка: люди не говорят иероглифами и не говорят буквами :) Они ими исключительно пишут, а говорят звуками, словами, предложениями и т.д. ()
Если же поставить вопрос так:
"Насколько сильно отличаются мышление людей, пишущих иероглифами, от людей пишущих буквами?"
- ответ будет:
"Не больше, чем мышление людей, умеющих писать, отличается от мышления людей, не умеющих писать."
Одним словом, несильно :)
Последние новости





