Sketch Engine

Задача
В таблице перечислены 18 лингвистических корпусов, которые представлены в системе Sketch Engine, и указано, какие из них находятся по запросам WELSH ‘валлийский’, TATAR ‘татарский’, DUTCH ‘нидерландский’ и RUSSIAN ‘русский’:
| WELSH | TATAR | DUTCH | RUSSIAN | GERMAN | ||
| 1 | British Academic Written English Corpus (BAWE) | + | + | |||
| 2 | Cambridge Academic English | |||||
| 3 | CHILDES German Corpus | |||||
| 4 | Chinese GigaWord 2 Corpus: Mainland, simplified | |||||
| 5 | Chinese Traditional Web (TaiwanWaC, Universal Sketch Grammar) | + | + | + | ||
| 6 | CoPEP — The Corpus of Portuguese from Academic Journals (v. 1.4) | + | + | |||
| 7 | English Wikipedia sample with Error annotations | + | ||||
| 8 | EUR-Lex judgments Dutch 12/2016 | + | ||||
| 9 | Lektor (Learner corpus of proofread and translations) | + | + | |||
| 10 | New corpus for English (NCI English) | + | ||||
| 11 | Polish Web (PolishWac, Morfeusz and TaKIPI tagger) | + | + | |||
| 12 | Russian web corpus (v2 with lempos) | + | ||||
| 13 | Swahili Web 2014 (SwahiliWaC) | + | ||||
| 14 | Swedish Web 2014 (svTenTen14) | |||||
| 15 | SwedishParole | |||||
| 16 | Tatar News (2000-2014), version with lempos | + | ||||
| 17 | Welsh Web 2013 (WelshWaC) | + | ||||
| 18 | Welsh web corpus | + |
Задание 1. Опишите, как работает поиск по списку корпусов.
Задание 2. Уточните ваше правило, если известно, что по запросу TATAR не находится LatinISE historical corpus v2.2, а по запросу DUTCH — EUR-Lex judgments Czech 12/2016.
Задание 3. Укажите номера всех корпусов из списка, которые найдутся по запросу GERMAN ‘немецкий’.
Примечание. Знание английского языка для решения задачи НЕ ТРЕБУЕТСЯ.
Подсказка 1
Заметьте, что в названии British Academic Written English Corpus (BAWE) нет буквы D, но есть W, E, L, S и H, а также T, A и R.
Подсказка 2
Обратите внимание на порядок следования букв из запроса в названиях корпусов.
Решение
Ответ на задание 1. Для того чтобы корпус нашёлся по некоторому запросу, в нём должны без учёта регистра встретиться (не обязательно рядом) все буквы из запроса в том же порядке или с перестановкой одной пары соседних букв. Например, по запросу WELSH:
British Academic Written English Corpus (BAWE)
Swahili Web 2014 (SwahiliWaC)
Welsh web corpus
Ответ на задание 2. Не допускается перестановка первых двух букв запроса:
LatinISE historical corpus v 2.2≠ TATAR
EUR-Lex judgments Czech 12/2016 ≠ DUTCH
Ответ на задание 3. По запросу GERMAN найдутся три корпуса:
3. CHILDES German Corpus
6. CoPEP — The Corpus of Portuguese from Academic Journals (v. 1.4)
7. English Wikipedia sample with Error annotations (с перестановкой M и R)
Следует особо отметить, что не найдётся корпус 4:
4. Chinese GigaWord 2 Corpus: Mainland, simplified (не допускается перестановка двух начальных букв)
Как видно, эта система решает задачу нечёткого поиска: она ищет названия, которые примерно соответствуют запросу. Правда, нельзя сказать, что она хорошо работает, потому что результаты её работы очень далеки от ожиданий пользователя.
Отдельный вопрос, на который не надо отвечать при решении задачи, но который интересно обсудить — как устроено выделение найденных букв в результатах поиска (оно делается и в самой поисковой системе, а не только в решении для наглядности).
1) Выбирается первая из подходящих букв: так, по запросу British Academic Written English Corpus (BAWE) будет выделено e в Written, а не E в English, хотя оба они находятся между W и l.
2) По возможности выделяются буквы без перестановок: British Academic Written English Corpus (BAWE), а не British Academic Written English Corpus (BAWE) по тому же запросу.
3) Если возможны несколько вариантов с перестановкой букв, выбирается тот вариант, в котором переставляемые буквы ближе к концу запроса:
CoPEP — The Corpus of Portuguese from Academic Journals (v. 1.4) (перестановка: RUSSIAN → RUSSINA),
а не
CoPEP — The Corpus of Portuguese from Academic Journals (v. 1.4) (перестановка: RUSSIAN → RUSSAIN).
Послесловие
Корпус — это большое электронное собрание текстов, а система Sketch Engine — это корпусный менеджер (см. Corpus manager), инструмент для работы с корпусами и исследований на их основе. Ресурс создан и поддерживается компанией Lexical Computing, основанной корпусным лингвистом и лексикографом Адамом Килгарифом (Adam Kilgarriff). С помощью Sketch Engine можно работать с корпусами множества языков и создавать собственные корпуса, не выходя из браузера.
В системе представлено около 500 корпусов 95 языков, но Sketch Engine — коммерческий проект. По бесплатной тридцатидневной подписке доступно около половины загруженных корпусов, а объем пользовательского корпуса ограничен миллионом слов. Конечно, бесплатной подпиской можно воспользоваться несколько раз, зарегистрировавшись на новую почту, но некоторые корпуса доступны и без регистрации. С полным списком корпусов можно ознакомиться тут. Нечеткий поиск, которому посвящена задача, можно производить в рабочей области (DASHBOARD):

По запросу «WELSH» действительно находятся не только валлийские корпуса (WelshWaC и Welsh web corpus, не попавшие на скриншот). Под замком — корпуса, недоступные при бесплатной подписке. Воспроизвести эксперимент можно после регистрации.
Удобный веб-интерфейс — преимущество основной версии проекта, но у него существует и другая версия с ограниченным функционалом — NoSketch Engine. Она находится в свободном доступе, ее можно скачать на компьютер и работать со своим корпусом, только для этого уже понадобятся навыки программирования.
Чем больше объем корпуса, тем больше интересных языковых явлений и закономерностей можно изучать на его основе. Объем некоторых корпусов Sketch Engine достигает десятков миллиардов слов. Откуда так много текстов? Если посмотреть на названия самых больших, то можно заметить слово «web». Такие корпуса созданы при помощи краулинга (см. Web crawler) — автоматического сбора текстов, которые находятся в свободном доступе в интернете. Для того чтобы корпуса, собранные из интернета, были лингвистически значимыми (да-да, важно не только количество, но и качество текстов), они проходят много этапов предобработки: удаление дублей, спама, «служебных» текстов (например, сниппетов) и т. д. Пользователи Sketch Engine тоже могут создавать корпуса краулингом, к такому корпусу мы обратимся в конце рассказа.
Еще раз посмотрев на названия, заметим, что есть несколько групп корпусов с общим именем (или фамилией) — Araneum, TenTen, CHILDES... Такие группы называют семействами корпусов. Каждый член «семьи» — корпус отдельного языка, а объединять семейство может общий тип или тематика текстов, технология их сбора и обработки. Самые большие и значительные семейства в Sketch Engine — это интернет-корпуса TenTen и Aranea. Например, корпусом русского языка в системе по умолчанию считается ruTenTen11 — он содержит более 14 миллиардов слов и доступен по бесплатной подписке.
Стоит обратить внимание и на корпуса Araneum Russicum: они, как и другие корпуса Aranea, в свободном доступе. В системе Sketch Engine есть не все, полный список можно найти только на сайте проекта Aranea. По названию этих корпусов тоже понятна их «природа»: в переводе с латыни araneum — это паутина (интернет), и тогда araneum russicum — русская паутина, а aranea — это когда паутин много, то есть собрание корпусов-паутин. В этой семье для каждого языка обычно есть по три брата: Minus, Maius и Maximum, они отличаются объемом. Русский старший брат Russicum Maximum содержит почти двадцать миллиардов слов, он доступен после бесплатной регистрации. На сайте Aranea поиск осуществляется при помощи инструментов NoSketch Engine, но, как мы говорили выше, у него не так много функций, как у основной версии.
Всего для русского языка в Sketch Engine есть двенадцать корпусов (с разной степенью доступа), но зачем так много? Всем знаком НКРЯ, самый авторитетный корпус русского языка: тексты для него отбираются экспертами, корпус снабжен богатой и качественной разметкой, имеет удобный интерфейс поиска. Однако НКРЯ, во-первых, ограничен по объему (около 300 миллионов слов в основном корпусе), во-вторых, в корпусе представлен русский литературный язык, но по нему сложно изучать современную живую речь. В статье А. Ч. Пиперски показано, как большие интернет-корпуса из Sketch Engine (и несколько других) могут быть полезны для изучения языковой вариативности, неологизмов, заимствований и разговорных языковых конструкций.
Полный список языков, представленных в системе, можно найти тут и, нажав на название языка, увидеть, какие корпуса есть для него. Кроме того, используя инструменты создания собственного корпуса, пользователи могут загрузить тексты на любом языке и работать с ними, даже если этот язык еще не представлен в Sketch Engine. Чтобы работать с корпусом (искать в нем слова, подсчитывать их частотность, смотреть на контексты), с текстами нужно сначала произвести несколько лингвистических операций. Отличие Sketch Engine от других известных корпусных менеджеров (например, AntConc и Voyant Tools) в том, что многие важные операции выполняются самой системой. Посмотрим, без каких шагов не обойдется ни одно серьезное корпусное исследование и что умеет корпусный менеджер:
1) Токенизация — разбиение текста на отдельные значимые единицы, токены. Есть два типа токенов — словарные и несловарные. Несловарными токенами, например, могут быть даты вида 12.01.2008, одиночные цифры. Знак препинания тоже может быть отдельным токеном. Но, например, Соединенные Штаты Америки — это один токен или три разных? А число 10 295 000 или номер телефона? А как делить на токены китайский текст? Всё это — нетривиальные проблемы компьютерной лингвистики, которые можно решать, используя разные алгоритмы токенизации. Для языков, для которых это возможно, Sketch Engine делит загруженный текст на токены просто по пробелам, а для других (например, китайского, японского, тайского) нужен более сложный подход.
2) Лемматизация — приведение слова к начальной форме. Для некоторых языков Sketch Engine умеет приписывать словам начальную форму. Это может понадобиться, если мы хотим посчитать частотность не отдельных форм слова, а всей лексемы. Например, чтобы в частотность слова стул «записались» частоты форм стулом, стулья, стульями и т. д. и в частотном списке текста или корпуса для этого слова была отведена только одна строчка. Или чтобы при поиске по лемме стул нашлись все возможные формы слова.
Иногда вместо лемматизации используется стемминг — нахождение основы слова. Например, при помощи стемминга формы cars, car's и cars' приводятся к основе car. Основа слова не всегда совпадает с корнем, но стемминг используется для агглютинативных языков, где легко выделить корень, а разные формы выражаются присоединением к корню набора аффиксов. Например, в Sketch Engine поиск по основе работает для турецкого языка в корпусе trTenTen. Лемматизация и стемминг объединяются термином нормализация, что означает приведение слова к нормальной форме (начальной форме-лемме или основе-стему).
В Sketch Engine все корпуса одного языка обрабатываются с использованием одних и тех же инструментов и, следовательно, имеют одни и те же алгоритмы лемматизации. В отличие от токенизации, для языков, которые не представлены в системе, лемматизация не работает. Так что, например, загрузить пользовательский корпус языка эсперанто в систему можно, но лемматизировать его не получится.
3) Морфологическая разметка. Для многих языков Sketch Engine умеет определять части речи и форму слова. Нужная морфологическая помета (тэг) выбирается из списка тэгов (тагсета), у каждого языка есть один или несколько тагсетов, полный список представлен тут. Корпус объемом в несколько миллиардов слов невозможно разметить вручную, поэтому разработка алгоритмов морфологической разметки — еще одна сложная и важная задача компьютерной лингвистики.
Почему же система называется именно Sketch Engine? Скетч — набросок, пробная версия рисунка. Несмотря на свою упрощенность и незаконченность, скетч передает идею: по нему уже понятно, что хочет изобразить художник, и можно представить, как выглядит оригинал и как будет выглядеть финальная версия рисунка. А Sketch Engine — это компьютерный инструмент, с помощью которого можно создать «скетч» слова, словосочетания, текста или даже целого корпуса. Например, Sketch Engine может показать пользователю контексты, в которых слово встречается в многомиллионном корпусе, и человек сможет сделать выводы о его семантике и употреблении. Или наоборот — Sketch Engine может выделить набор слов, характеризующих большой корпус, и это поможет нам узнать что-то о свойствах и содержании этого корпуса. Посмотрим, какие скетчи умеет рисовать наш корпусный менеджер.
Ключевая функция называется Word Sketch — скетч слова. Этот инструмент ищет все контексты, в которых употребляется слово, делит их на типы и выдает табличную сводку. Скетч слова в корпусе — это набросок портрета слова в языке. Посмотрим, например, на фрагмент скетча, который получился из миллиона употреблений глагола родиться в корпусе ruTenTen:
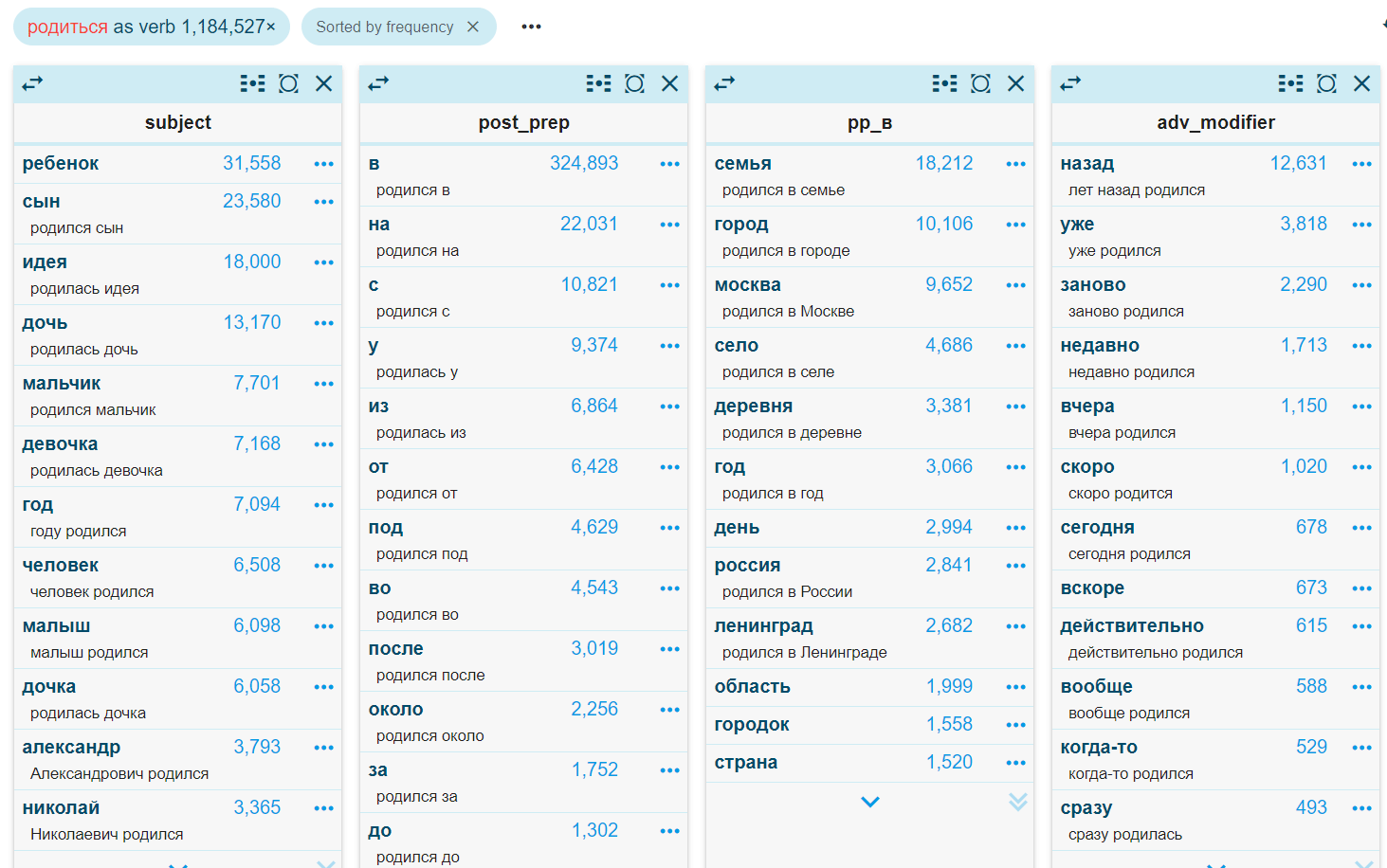
Каждый столбец — это тип словосочетания, столбцы отсортированы по убыванию частотности коллокатов (под коллокатами мы подразумеваем слова, часто встречающиеся в корпусе вместе с заданным словом; см. Коллокация). Например, в первом столбце — существительные, которые могут быть субъектом действия. Уже по этому столбцу заметно, что слово часто употребляется как в прямом значении — родился ребенок, родился сын, так и в переносном — родилась идея. (На двух последних словах Sketch Engine немного «заглючил» и сначала посчитал, что начальные формы слов Александрович и Николаевич — это Александр и Николай, а потом решил, что полученные слова в именительном падеже — субъекты действия.) Во втором столбце — самые частотные предлоги, употребляющиеся со словом, и так далее. Правила, по которым выделяются коллокаты, прописываются в «скетчевых грамматиках», отдельных для каждого языка. Для своих задач пользователи могут редактировать грамматики, которые уже есть в Sketch Engine, и создавать новые.
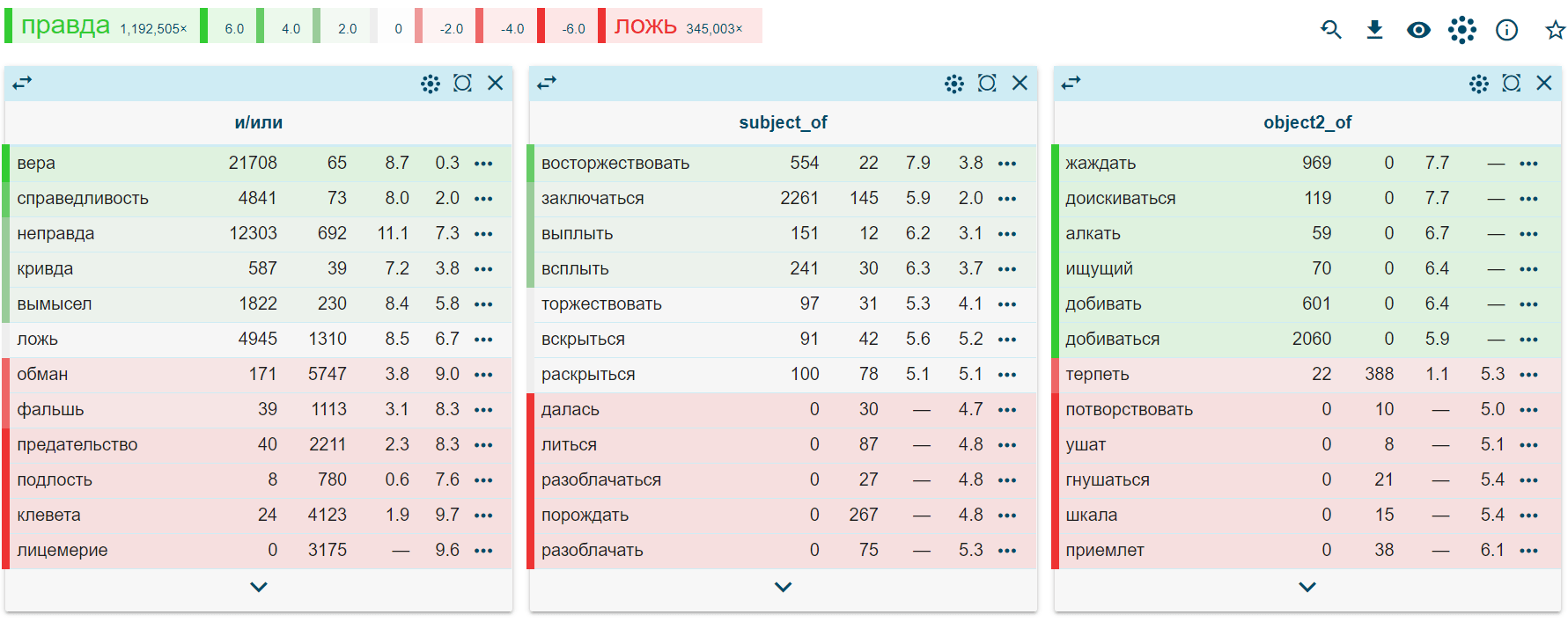
Скетчи двух слов можно сравнить при помощи инструмента Word Sketch Difference. Сравним, например, скетчи слов правда и ложь. Зеленым выделены контексты, в которых чаще встречается первое слово, красным — те, в которых чаще встречается второе, а белым — общие для двух слов. Из столбца «subject_of» мы можем узнать, что всплывает чаще правда, а торжествует и то и то, из столбца «object2_of» (прямой объект, второй актант) — что правды жаждут или алчут, а лжи потворствуют, гнушаются ее...
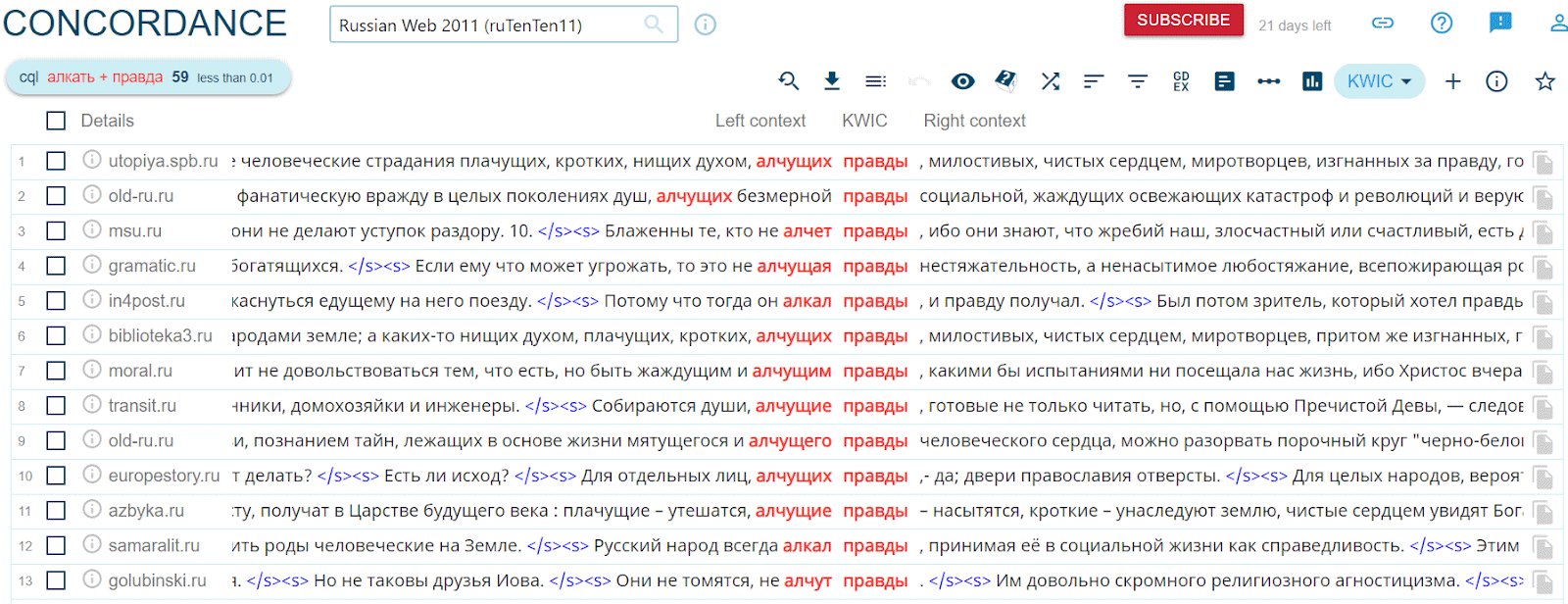
Примеры употребления коллокаций можно получить, если нажать на три точки справа от слова и выбрать инструмент Concordance:
А как «набросать скетч» целого корпуса, чтобы в общих чертах понять, тексты каких жанров и на какие темы в нем содержатся? Например, при помощи инструмента Wordlist посмотреть на самые частотные слова корпуса. Вверху частотного списка любого корпуса будут служебные слова и местоимения, интереснее посмотреть, например, на самые частотные существительные:
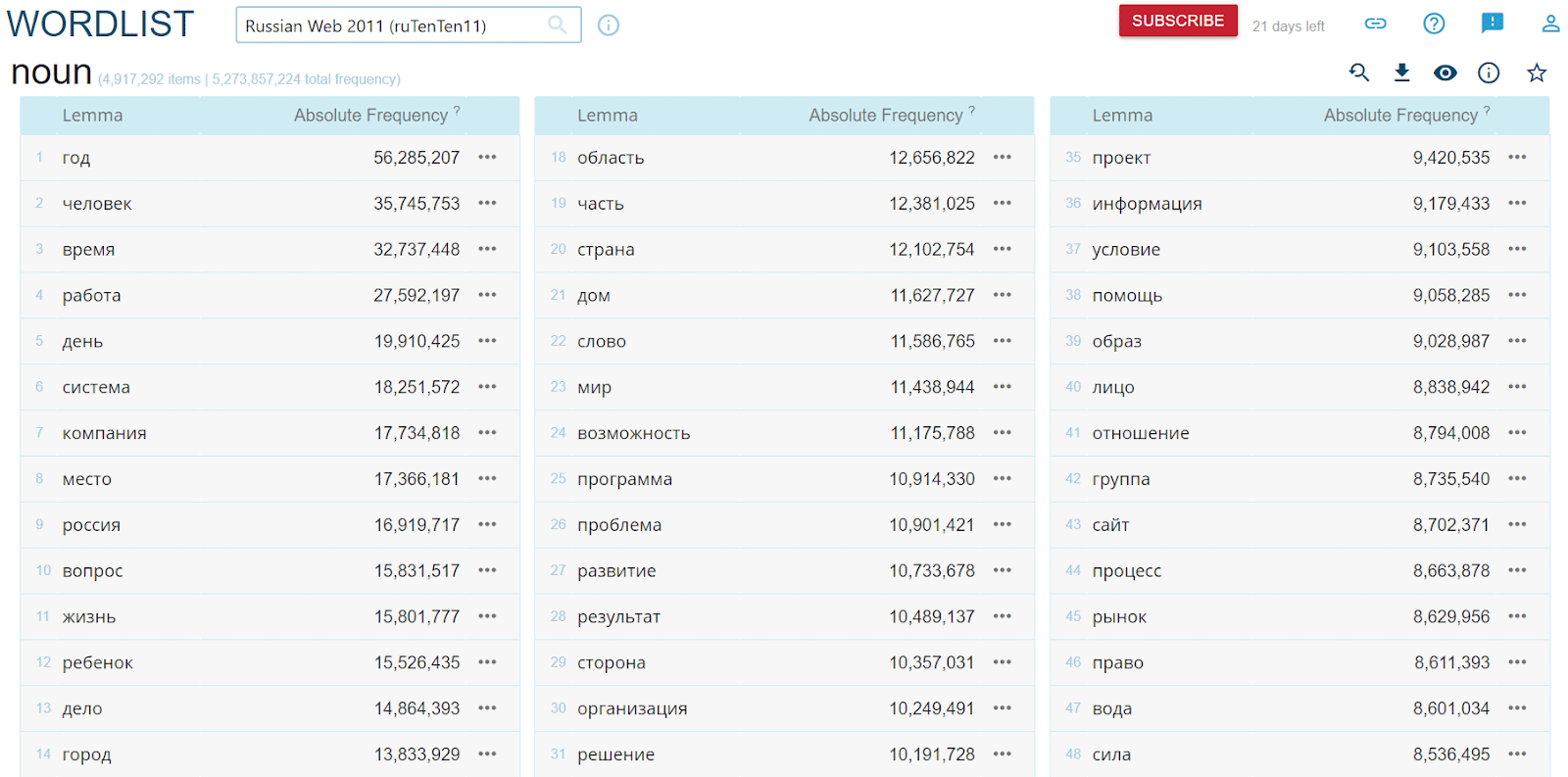
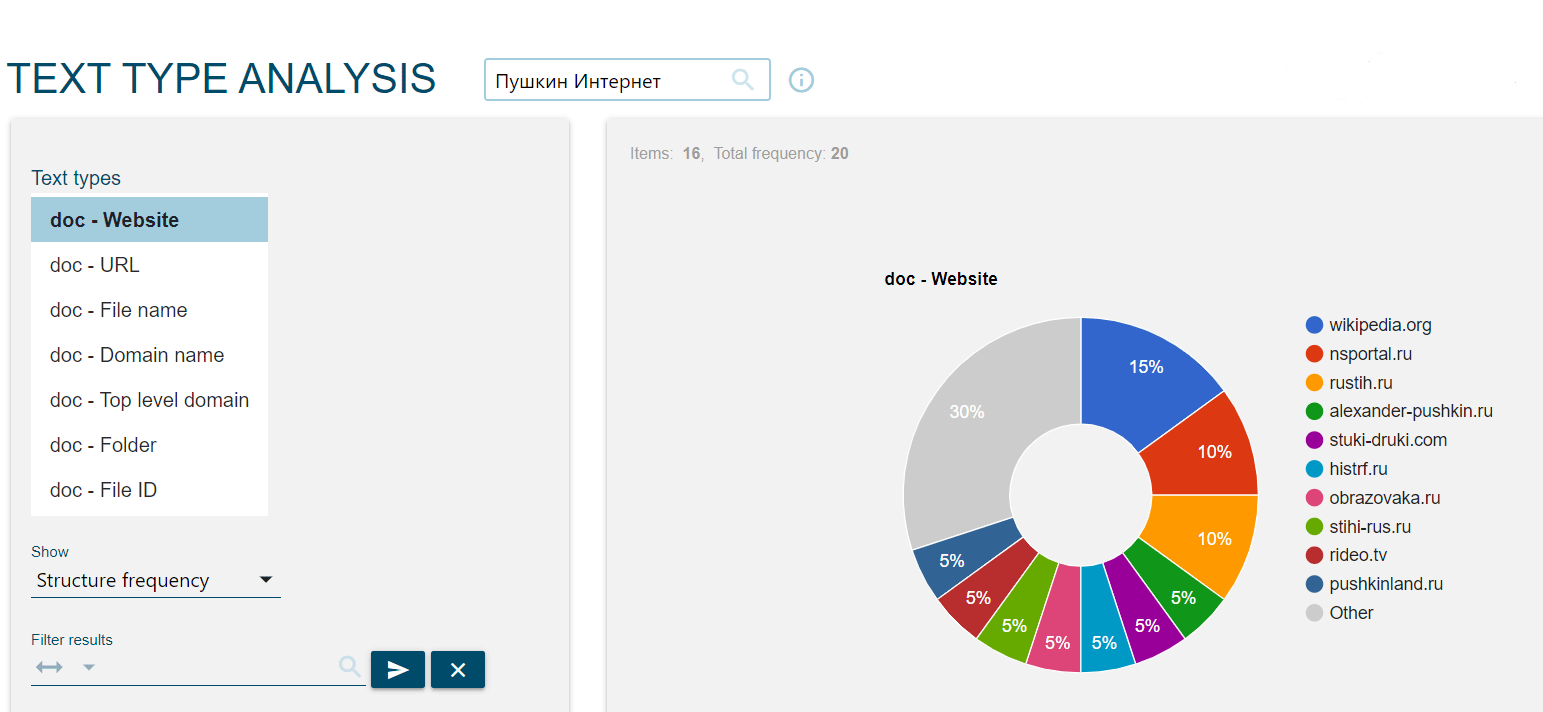
Год, человек, работа, город, компания, Россия, чуть ниже — рынок, организация, проект... По этому частотному списку можно предположить, что большинство текстов в корпусе ruTenTen — это новости. Можно узнать, с каких сайтов взяты тексты: для этого на вкладке Dashboard нужно нажать Corpus info, выбрать Text types, а затем Website. Источников очень много, но больше всего текстов для корпуса и правда взято с новостных сайтов.
А как с помощью Sketch Engine сравнить корпуса и понять, что отличает их друг от друга? Для этого в Sketch Engine есть инструмент Keywords. Он помогает выделить список ключевых слов корпуса — слов, которые характерны для одного (фокусного) корпуса по сравнению с другим (референсным). Каждому слову в фокусном корпусе присваивается коэффициент «ключевости» (как он вычисляется, подробно рассказано тут).
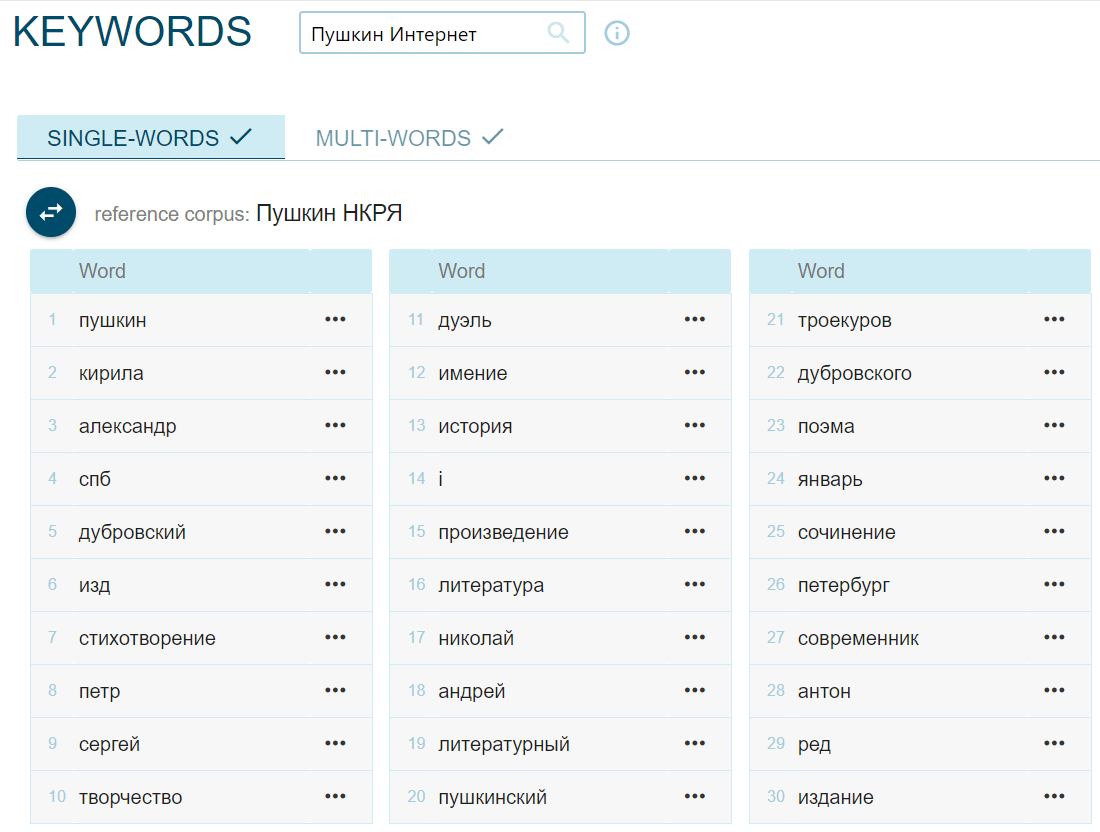
Чтобы показать, как это работает, создадим два корпуса — первый будет собран из интернета по запросам «А. С. Пушкин», «Пушкин» и «Александр Сергеевич Пушкин», а во второй мы загрузим стихотворения А. С. Пушкина из Поэтического подкорпуса НКРЯ. В интернет-корпус тоже могли попасть страницы со стихотворениями, но больше было страниц с биографией поэта и образовательных сайтов:
Фокусным корпусом сделаем первый, а референсным — второй, в настройках выберем параметры N = 100 и lemma (lowercase) и получим слова, которые могли встретиться в обоих корпусах, но более характерны для корпуса «Пушкин Интернет», чем для корпуса поэзии:
Затем поменяем корпуса местами и при тех же параметрах посмотрим, какие слова более характерны для корпуса поэзии:
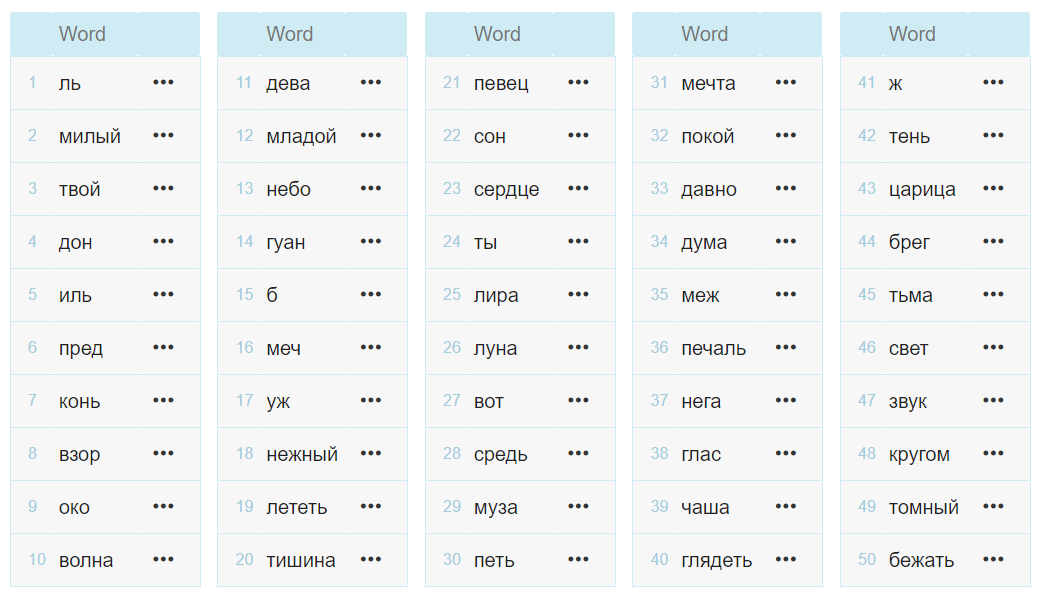
Оказывается, что для корпуса сайтов о Пушкине более характерны слова творчество, стихотворение, произведение, литературный, сочинение, издание, сама фамилия поэта и т. п. В корпусе стихотворений таких слов не встретилось (или было незначительно мало по сравнению с интернет-корпусом), но встретились «типичные» поэтические слова: ль, иль, око, взор, уж, б, лира, сердце... Результат кажется очень предсказуемым, но напомним, что корпусный менеджер ничего не знал про корпуса, только посчитал слова в них и вычислил «ключевость». Точно так же можно найти и проанализировать ключевые словосочетания (Multi-words) или выделить ключевые слова какого-либо корпуса относительно корпуса всего языка.
Обо всех возможностях Sketch Engine и типах представленных в нем корпусов, которые мы не упомянули, можно прочитать на сайте проекта. А больше о том, как в системе создать собственный корпус, и даже о том, как провести на его основе филологическое исследование, читайте в материале «Системного Блока» (часть 1 и часть 2).
Автор задачи — Александр Пиперски.
Автор послесловия — Дарья Балуева.
Последние задачи






