Язык из ниоткуда

Задача
В праиндоевропейском языке — предке русского и других славянских языков, древнегреческого и древнеиндийского языка (санскрита), а также многих других языков — существовали глухие согласные (напр., p, t, k; иногда их называют латинским словом tenues), звонкие согласные (напр., b, d, g; mediae) и звонкие придыхательные согласные (напр., bʰ, dʰ, gʰ; mediae aspiratae). Они сохранились в таком виде в древнеиндийском, а в других языках отражаются разными способами: например, в древнегреческом звонкие придыхательные стали глухими придыхательными (pʰ, tʰ, kʰ), а простые звонкие и глухие остались без изменений.
Даны 14 русских слов и близкие к ним по форме и значению древнеиндийские и/или древнегреческие слова, которые с большей или меньшей степенью надёжности считаются родственными им:
басня др-гр. pʰōnē ‘голос’ бедро др.-инд. pad-, др.-гр. pod- ‘нога’ брат др.-инд. bʰrātar- ‘брат’, др.-гр. pʰrātōr ‘член братства’ вдова др.-инд. vidʰavā ‘вдова’ горсть др.-гр. agostos ‘горсть’ деру др.-гр. derō ‘драть’ долгий др.-инд. dоrgʰa-, др.-гр. dolikʰos ‘долгий’ камень др.-гр. akmōn ‘наковальня’ который др.-инд. katara- ‘который из двух’ месть др.-гр. mistʰos ‘плата’ песня др-гр. pʰōnē ‘голос’ свободный др.-инд. svapati- ‘свободный’ тёплый др.-инд. tapu- ‘тёплый’ ядро др.-инд. antra-, др.-гр. entera ‘внутренности’
Примечание. Древнеиндийские и древнегреческие слова приводятся в латинской транскрипции. Чёрточка над гласной обозначает долготу. Большинство древнеиндийских слов приводится в форме основы (без окончания), что показано дефисом в конце записи.
Задание 1. Установите, как отражаются в славянских языках праиндоевропейские глухие, звонкие и звонкие придыхательные согласные, если известно, что общие правила соблюдаются в девяти из четырнадцати данных слов, а в пяти — не соблюдаются.
Задание 2. Найдите пять слов-исключений.
Указание. На все согласные кроме тех, которые перечислены в условии, и на гласные обращать внимание при решении не следует.
* * *
Тот факт, что эти пять слов не подчиняются общим правилам, наталкивает на мысль, что они вовсе не родственны приведённым древнегреческим и древнеиндийским словам, а имеют другое происхождение. Однако в 1983 году австрийский учёный Георг Хольцер нашёл возможное решение этой проблемы (которое, правда, так и не стало общепризнанным). Обратив внимание, что некоторые славянские слова очень похожи по смыслу и звучанию на слова других индоевропейских языков, но не соответствуют общим правилам звуковых изменений, он предположил, что это заимствования из несохранившегося языка, который тоже происходит из индоевропейского. Хольцер назвал этот язык темематическим. Праиндоевропейские согласные изменялись по строгим правилам и в темематическом языке — но не по таким, как в древнегреческом и славянских языках. Те пять слов, которые в заданиях 1–2 кажутся исключениями, Хольцер перечисляет среди заимствований из темематического языка в славянские языки.
Задание 3. Установите, как отражаются в темематическом языке праиндоевропейские глухие, звонкие и звонкие придыхательные согласные.
Задание 4. Какое слово, подчиняющееся общему правилу, теоретически могло бы быть заимствованием из темематического языка?
Задание 5. Объясните, почему Хольцер назвал восстановленный им язык темематическим.
Задание 6. Для второго по счёту из пяти слов-исключений в русском языке есть близкие по значению слова, которые происходят от того же праиндоевропейского корня, но соответствуют общим правилам для славянских языков, а не заимствованы из темематического языка. Приведите любое из этих слов.
Подсказка 1
Посмотрите, что̀ соответствует по-русски древнеиндийским и древнегреческим глухим согласным p, t и k. Найдите три слова-исключения.
Подсказка 2
Посмотрите, что̀ соответствует по-русски праиндоевропейским звонким придыхательным, то есть древнеиндийским звонким придыхательным bʰ, dʰ и gʰ и древнегреческим глухим придыхательным pʰ, tʰ и kʰ. Найдите два слова-исключения.
Подсказка 3
Слово «темематический» образовано от латинских слов. Конечно, знание латинского языка для решения задачи не требуется, но если поискать, то вы найдёте в условии три латинских слова.
Решение
Распределим все данные в условии слова в зависимости от соответствий между русскими и праиндоевропейскими классами звуков.
| п р а и н д о е в р о п е й с к и й | ||||
| глухие | звонкие | звонкие придыхательные |
||
| р у с с к и й |
глухие |
брат |
месть |
|
| звонкие |
бедро |
бедро |
басня |
|
Ясно, что в столбцах «глухие» и «звонкие придыхательные» одна из ячеек соответствует общему правилу, а другая — исключению. Исключений должно быть пять; значит, это левая нижняя и правая верхняя ячейки. В ячейку «звонкие — звонкие» попали и закономерные слова (горсть, долгий), и исключение (бедро); следовательно, праиндоевропейские звонкие согласные в любом случае отражаются одинаково и не составляют проблемы.
Ответ на задание 1. Отражение праиндоевропейских согласных в славянских языках:
глухие = глухие (p, t, k = п, т, к)
звонкие = звонкие (b, d, g = б, д, г)
звонкие придыхательные → звонкие (bʰ, dʰ, gʰ = б, д, г)
Ответ на задание 2. Исключения: бедро, месть, песня, свободный, ядро.
Ответ на задание 3. Отражение праиндоевропейских согласных в темематическом языке:
глухие → звонкие (p, t, k = b, d, g)
звонкие = звонкие (b, d, g = b, d, g)
звонкие придыхательные → глухие (bʰ, dʰ, gʰ = п, т, к)
Именно таким образом получаются формы, которые в результате заимствования могли привести к русским словам бедро, месть, песня, свободный, ядро.
Ответ на задание 4. В слове деру праиндоевропейскому звонкому согласному соответствует звонкий, но так ведут себя и славянские языки, и темематический. Чтобы не предполагать заимствование из незасвидетельствованного языка там, где можно без этого обойтись, в условии оно отнесено к группе исконных слов.
Ответ на задание 5. Опишем то же, что в ответе на задание 3, но с помощью латинских терминов, которые приводятся в начале условия задачи:
Te → Me: tenues (глухие) переходят в mediae (звонкие)
MA → T: mediae aspiratae (звонкие придыхательные) переходят в tenues (глухие)
Из этих сокращений и получается TeMeMAT (немецкое Temematisch, русское темематический).
Ответ на задание 6. Второе по счёту слово исключение в списке — это месть, где т соответствует древнегреческому глухому придыхательному, а значит, праиндоевропейскому звонкому придыхательному. По общим правилам в славянских языках должно было бы получиться д, и действительно, мы находим такие слова, как мзда и возмездие.
Послесловие
Самая простая модель истории человеческих языков, которой лингвистов учат на первом курсе, выглядит примерно так: существует язык, носители которого разделяются на несколько живущих обособленно групп; в каждой из этих групп происходят разные звуковые изменения, то есть действуют правила вида «звук A переходит в звук B в такой-то позиции (например: на конце слова, между гласными, везде и т. п.)». Когда таких изменений накапливается много, на месте одного языка предка возникает несколько языков-потомков, которые дальше развиваются по той же схеме. На рис. 1 вы найдёте генеалогическое древо, которое показывает такое развитие для так называемого праиндоевропейского языка, существовавшего примерно 8 тысяч лет назад: именно из него возникли русский, английский, хинди, французский, греческий и множество других языков. На самом деле это древо ещё разветвлённее: здесь показаны только ныне существующие языки-потомки, причём далеко не все. Подробнее об этом — в лекции Андрея Зализняка «Об исторической лингвистике» или в главе 12 из книги Владимира Алпатов «Языкознание. От Аристотеля до компьютерной лингвистики».

Важная задача исторической лингвистики — отмотать историю языков назад:
1) сделать реконструкцию, то есть понять, как то или иное слово выглядело в праязыке;
2) установить, какие звуковые изменения привели к тем формам, которые наблюдаются в языках-предках.
Результат такой работы для слова со значением "вдова’ выглядит примерно так. На уровне праиндоевропейского языка реконструируется форма, которая выглядит примерно как h₁widʰeweh₂ (h₁ и h₂ — особые согласные, похожие на русское х или английское h; про эти согласные можно подробнее почитать в задаче «Исчезнувший согласный»). Изменения, которые произошли на пути от этой формы к санскритской, таковы:
1) e → a рядом с h₂: h₁widʰewah₂;
2) h₂ выпало на конце слова после гласного, но оставило след в виде удлинения предшествующего гласного: h₁widʰewā;
3) h₁ выпало в начале слова: widʰewā;
4) e → a: widʰawā;
5) w → v: vidʰavā.
Для русского языка цепь изменений будет подлиннее, причём вполне возможно, что первые три изменения произошли ещё на том этапе, когда язык-предок русского и санскрита был единым (но греческий уже отделился от него, о чём мы поговорим ниже; попробуйте найти этот этап на дереве на рис. 1).
1) e → a рядом с h₂: h₁widʰewah₂;
2) h₂ выпало на конце слова после гласного, но оставило след в виде удлинения предшествующего гласного: h₁widʰewā;
3) h₁ выпало в начале слова: widʰewā;
4) звонкие придыхательные → простые звонкие, в том числе dʰ → d: widewā;
5) e → o перед сочетанием w + гласный заднего ряда: widowā;
6) i → ĭ (очень краткий гласный): wĭdowā;
7) ā → a: wĭdowa;
8) очень краткое ĭ выпадает перед слогом с нормальным гласным: wdowa;
9) w → v: vdova;
10) o → a в безударном слоге: vdava.
Как видно, последний переход является частью русского литературного языка, но на письме он не отразился: мы пишем вдова в соответствии с позднедревнерусским произношением.
Восстановить праиндоевропейскую форму и понять, как происходили звуковые изменения, мы можем благодаря тому, что слова vidʰavā и вдова (а также латинское vidua, английское widow и т. д.) имеют одинаковое значение и достаточно похожи по звучанию. Если набрать достаточно много таких слов, то можно построить непротиворечивую и убедительную систему переходов. Например, добавив к рассмотрению ещё несколько пар типа др.-инд. madʰu- ~ рус. мёд, др.-инд. dʰūma- ~ рус. дым, мы понимаем, что, действительно, существует регулярное соответствие др.-инд. dʰ ~ рус. д. А посмотрев на случаи типа др.-инд. dvau ~ рус. два, др.-инд. dama- ~ рус. дом, мы видим, что существует и регулярное соответствие др.-инд. d ~ рус. д. Тогда нам ничего не остаётся, как предполагать, что в языке-предке были простые звонкие и звонкие придыхательные согласные, а в славянских языках придыхание в какой-то момент потерялось (правило 4 в списке для русского выше). С помощью таких мыслительных операций и восстанавливается история языков.
Если бы всё было так стройно и логично, мы бы легко могли проследить историю всех человеческих языков до самого начала, то есть на 100—200 тысяч лет назад. Кроме того, мы бы легко понимали языки, которые разошлись с нашими много тысяч лет назад, например тот же древнеиндийский или английский. Но в реальной жизни эта идеальная схема подвергается искажениям и зашумлению. Да, можно придумать искусственный древнеиндийский текст, в котором всё будет идеально соответствовать русскому (порешайте задачу Арона Долгопольского и Андрея Зализняка), но вообще-то на этом языке без подготовки непонятно ничего. Вот, например, начало самого первого гимна «Ригведы», чтобы в этом убедиться:
aghnimīḷe purohitaṃ yajñasya devaṃ ṛtvījam |
hotāraṃ ratnadhātamam ||
aghniḥ pūrvebhirṛṣibhirīḍyo nūtanairuta |
sa devāneha vakṣati ||
А вот русский перевод этого фрагмента, сделанный Татьяной Елизаренковой:
Агни призываю я — во главе поставленного
Бога жертвы (и) жреца,
Хотара обильнейшесокровищного.
Агни достоин призываний риши —
Как прежних, так и нынешних:
Да привезёт он сюда богов!
Откуда же берётся такое несходство, если различий в фонетических изменениях между русским и древнеиндийским было не так уж много? Слова для ‘вдовы’ же в общем остаются похожими. Но дело в том, что изменения происходят на всех уровнях языка: не только в фонетике, но и в грамматике, и в лексике.
Может оказаться так, что слова в ходе своего фонетического развития приобретают непохожие приставки или суффиксы, или в одном языке приобретают что-то, а в другом нет. Дело в том, что фонетические изменения редко приводят к удлинению слов: обычно длина слова остаётся неизменной, либо сокращается. Видно, что восьми праиндоевропейским звукам слова ‘вдова’ в санскрите соответствуют шесть звуков, а в русском — пять. Если таких сокращающих изменений в языке много, спустя какое-то время слова просто перестанут различаться. Поэтому по-болгарски, например, ‘вдова’ будет вдовица — такое же трёхсложное слово из семи звуков, как между изменениями 2 и 3 в списках выше, то есть можно сказать, что произошло возвращение примерно на 6000 тысяч лет назад. Важно, что искать соответствия для болгарского -иц- в санскритском слове vidʰavā бесполезно. В тексте гимна из «Ригведы» мы находим части puro- и pūrve-, в которых с трудом опознаются части слов прежний, перед, первый, но то, что следует за выделенными частями в русском, древнеиндийского соответствия не имеет.
А ещё слова просто заменяются другими. Например, сравнивать русское слово вдова и английское widow можно, а русское слово вдова и шведское änka с тем же значением бессмысленно: скандинавские вдовы (швед. änka, норв. / дат. enke) образованы от корня ‘один’ (швед. / норв. / дат. en), то есть ‘вдова’ — это буквально ‘одиночка’. Важный источник замен — заимствования: например, русское слово глаз не соответствует названию глаза в других славянских языках (украинское око, белорусское вока, польское oko, словенское oko и т. д.), потому что это заимствование из немецкого Glas: буквально русский глаз — это ‘стекляшка’.
Когда мы изучаем историю языков, очевидные заимствования можно сразу исключить из рассмотрения. Например, никто не станет восстанавливать звуковые изменения в праиндоевропейском языке, сравнивая русское слово компьютер c бенгальским kompiuṭar, или тем более говорить о родстве русского с индонезийским, в котором тоже есть слово komputer. Однако для более древних языковых состояний заимствования не всегда легко идентифицировать, а особенно нелегко понять, когда мы имеем дело с заимствованием из близкородственного языка.
Дело в том, что языки не делятся так решительно, как это изображает генеалогическое древо. Их носители продолжают в той или иной степени контактировать друг с другом, причём часто они неплохо понимают друг друга, и это приводит к тому, что заимствования проникают из одного языка в другой очень естественно и незаметно. Большинство таких влияний — это по сути небольшие сдвиги в частотности одинаково звучащих слов: если мы видим, что какое-то слово встречалось в языке A часто, а в близкородственном языке B редко, а потом стало употребляться в B чаще, есть вероятность, что это влияние языка A. Даже если есть небольшие фонетически различия, они чаще всего легко пересчитываются: например, русское большевик даёт украинское більшовик, а не *большевік.
Но всё-таки иногда пересчёт не происходит: например, если заимствование и старое слово разошлись по значению. Так, шведское skaffa ‘добывать’ заимствовано из немецкого schaffen ‘создавать; добывать’, и это хорошо видно, потому что есть и слово skapa ‘создавать’. Ещё одна причина не пересчитывать: если слово плохо делится на морфемы. Например, современное русское слово чевапчичи заимствовано из сербского ћевапчићи, в котором чић — уменьшительный суффикс, который соответствует русскому -чик- (как в слове супчик): соответственно, пересчёт дал бы чевапчики. Это было бы вполне естественно, потому что это действительно небольшие котлетки, но в русском языке, в отличие от сербского, нет слова чевап, так что морфемный состав слова при заимствования остался непонятным. А, например, по украинскому слову каракатиця можно понять, что это заимствование из русского каракатица, а не исконное слово: дело в том, что это слово восходит к праславянскому корню *kork- ‘нога, конечность’ (ср. окорок и серб. крак ‘голень’), то есть каракатица — это просто ‘ногатая’, но это слово по-восточнославянски должно было выглядеть как корокатица. Однако слово корок не сохранилось и состав слова стал непонятным, так что в русском письме стало отражаться аканье; в украинском аканья быть не должно, а значит, это русское заимствование.
Когда заимствования из близкородственного языка многочисленны, но при этом звуковой адаптации не подвергаются, возникает большой пласт фонетически опознаваемых заимствований. Такую ситуацию мы находим в русском, где очень много заимствований из церковнославянского языка, который является южнославянским. В частности, для этих заимствований характерно неполноласие ра, ла на месте исконно русских оро, оло: град, враг, мрак, смрад, страна, глас, глава. Как мы видим, эти слова сосуществуют с исконно русскими словами город, ворог, морок, сторона, голос, голова, но статус в каждой паре особый: где-то более нейтрально исконное слово (город, голос), где-то наоборот (враг); где-то слова разошлись по значению (мрак — не то же, что мо́рок; страна — не то же, что сторона; глава — не то же, что голова); есть случаи, когда заимствование не имеет пары (смрад; остался только след в слове смородина).
Примерно такую ситуацию Георг Хольцер предлагает постулировать для балто-славянских языков, но с той разницей, что язык — источник многочисленных заимствований нам неизвестен ниоткуда, кроме самих этих слов. Хочется, конечно, возразить, что это порочный круг, но есть вполне разумные основания его постулировать: дело в том, что иначе у нас остаётся довольно много слов, которые хорошо сближаются по значению, но различаются на один-два несводимых к одному источнику звука, и непонятно, что с этим делать. Можно искать спасение в более надёжных фонетически, но менее убедительных по значению этимологиях: например, в этимологическом словаре Ю. Покорного русское бедро сближается с армянским port ‘пупок’, чтобы получить правильные соответствия согласных. Но всё-таки идея связи бедра и ноги (др.-инд. pad-, др.-гр. pod-) кажется лучше. Особенно убедительный случай — слово свободный; дело в том, что по-древнерусски есть неизменяемое прилагательное свободь ‘свободный’ (да мы отъ грѣхъ свободь будемъ ‘пусть мы будем свободны от грехов’) — такое же по форме, как мы сейчас находим в устойчивом сочетании особь статья. Объяснить его происхождение позволяет тот факт, что это точное соответствие по форме древнеиндийскому svapati- из sva- ‘свой’ + pati- ‘господин’: ь на конце происходит из краткого i (это то, что мы в примере с ‘вдовой’ писали как ĭ), а двусложный нечленимый славянский корень выглядит странно, а древнеиндийский хорошо объясняет его структуру. Однако глухость-звонкость двух согласных при этом не сходятся.
Конечно, объяснения Хольцера не всегда убедительны, и слависты много спорят об отдельных словах (в задачу отодобраны наименее проблемные примеры). Остаётся только надеяться, что когда-нибудь следы темематического языка найдутся в более явном виде. Такое иногда случается в исторической лингвистике: например, именно так были подтверждены данными хеттского языка h-образные (ларингальные) согласные, два из которых реконструируются в слове ‘вдова’. В случае с темематическим языком такие находки, конечно, крайне маловероятны, поскольку там, где жили предки балтов и славян 3–4 тысячи лет назад, а значит, и предполагаемые носители темематического языка (рис. 2), не было письменности, но вдруг нам повезёт?..
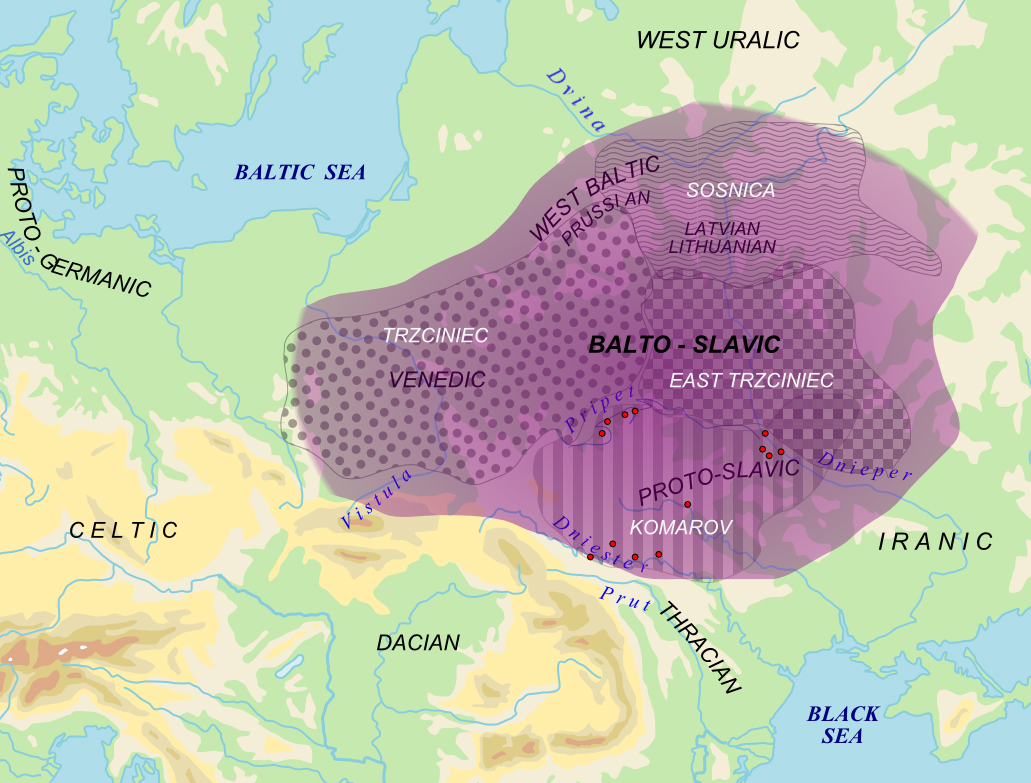
Область балто-славянского диалектного континуума и венедского языка на фоне археологических культур эпохи бронзы. Изображение с сайта commons.wikimedia.org
Последние задачи










Рис. 1. Генеалогическое древо индоевропейской семьи языков. Источник: Th. Cole, E. Siebert-Cole. Family Tree of Languages — Part 1: Indo-European (2024)