Soundex

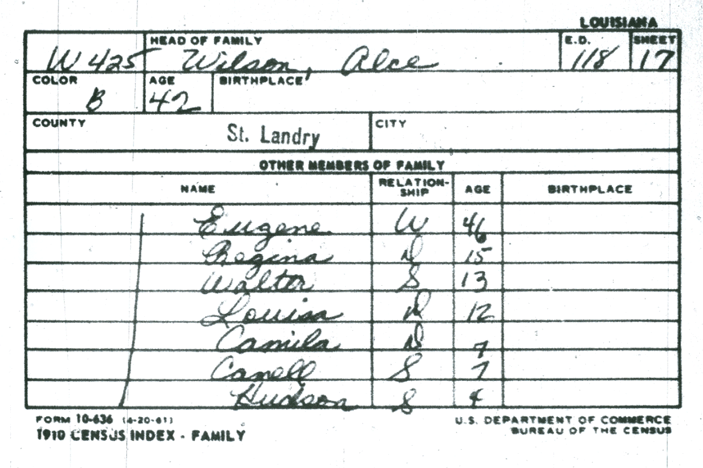
Soundex — это алгоритм для кодирования имён собственных. Его создали в 1918–1922 гг. в США Роберт Расселл и Маргарет Кинг Оделл, чтобы облегчить поиск похоже звучащих фамилий. В середине XX века Soundex широко использовался в США при анализе результатов переписей населения 1890–1920 гг. Ниже дан пример карточки с данными переписи населения 1910 г. Здесь вы видите, что код Soundex для фамилии Wilson выглядит как W425:
Задача
Дан список фамилий и соответствующих им кодов Soundex в перепутанном порядке. Некоторые символы пропущены:
Allaway, Anderson, Ashcombe, Buckingham, Chapman, Colquhoun, Evans, Fairwright, Kingscott, Lewis, Littlejohns, Stanmore, Stubbs, Tocher, Tonks, Whytehead
S312, T␣6␣, ␣5␣3, C42␣, T520, L␣42, A536, C155, ␣623, S356, ␣252, ␣152, ␣330, A251, A400, L2␣0
Задание 1. Опишите пошагово, как генерируется код Soundex.
Задание 2. Установите соответствия между фамилиями и кодами Soundex и вставьте пропущенные символы.
Задание 3. Постройте коды Soundex для следующих фамилий: Ferguson, Fitzgerald, Hamnett, Keefe, Maxwell, Razey, Shaw, Upfield.
Подсказка
Каждый код состоит из буквы и трёх цифр. Буква повторяет первую букву фамилии, а цифры кодируют согласные, которые содержатся в этой фамилии дальше.
Решение
Все коды Soundex состоят из латинской буквы и трёх цифр. Нетрудно догадаться, почему код для фамилии Wilson начинается на W: потому что это первая буква этой фамилии.
После того как стало ясно, что первая буква сохраняется, задача распадается на шесть небольших задач с перепутанными соответствиями:
Allaway, Anderson, Ashcombe
A536, A251, A400Chapman, Colquhoun
C42␣, C155Lewis, Littlejohns
L␣42, L2␣0Stanmore, Stubbs
S312, S356Tocher, Tonks
T␣6␣, T520Buckingham, Evans, Fairwright, Kingscott, Whytehead
␣5␣3, ␣623, ␣252, ␣152, ␣330
Вспомним, что Soundex — алгоритм, разработанный для поиска похоже звучащих слов. Вероятно, цифры должны кодировать какие-то характерные звучания. Можно выдвинуть гипотезу, что они соответствуют согласным буквам, которые встречаются в фамилии. Правда, цифр только шесть — значит, одна и та же цифра кодирует целые группы согласных.
Эти группы таковы:
| bpv(f) | cgjkqs(xz) | dt | l | mn | r |
| 1 | 2 | 3 | 4 | 5 | 6 |
Классификация букв в Soundex более или менее соответствует классификации звуков по тому, как они произносятся: в группу 1 входят согласные, произносимые с участием губ; в группу 2 — согласные, произносимые с помощью задней части языка, и свистящие; в группу 3 — переднеязычные смычные (d и t); в группу 5 — носовые. Исходя из этого, можно распределить по группам и те буквы, которые мы не видели в условии (в таблице они даны в скобках). Буква f попадёт в группу 1 к губным согласным (там уже находится v, пара f по глухости-звонкости), а x и z — в группу 2 (x состоит из k и s, которые находятся в группе 2, а z — звонкая пара к s). Буквы h и w в эту таблицу не вошли: они при генерации кода Soundex игнорируются. То же касается буквы y, которая в английском языке считается гласной.
Можно заметить, что сочетаниям согласных из одной группы соответствует только одна цифра в коде. Например, из данных в условии кодов фамилии Kingscott может соответствовать только ␣5␣3, в котором 5 отвечает за n, 3 — за t, а цифра в середине должна отвечать за g, s и c (очевидно, это будет цифра 2).
Нули в коде соответствуют случаям, когда согласных не хватило на то, чтобы заполнить три позиции. Например, можно установить, что Allaway — это A400, где двум l соответствует 4, а a, w, a и y в кодировании не участвуют.
Ответ на задание 1. Обобщая все эти наблюдения, можно построить алгоритм кодирования. Важно обратить внимание на порядок операций, чтобы он позволил получить все коды без ошибок.
1. Оставить первую букву неизменной.
2. Удалить h и w.
3. Заменить все согласные на цифры (буквы, наиболее частые чтения которых похожи, объединяются в группы):
bfpv cgjkqsxz dt l mn r 1 2 3 4 5 6 4. Две или более одинаковых цифры подряд сократить до одной.
5. Удалить все гласные (a, e, i, o, u, y).
6. Оставить только первые три цифры или дописать нули справа, чтобы длина кода составила одну букву и три цифры.
Ответ на задание 2 (восстановленные символы подчёркнуты).
Allaway: A400, Anderson: A536, Ashcombe: A251, Buckingham: B252, Chapman: C155, Colquhoun: C425, Evans: E152, Fairwright: F623, Kingscott: K523, Lewis: L200, Littlejohns: L342, Stanmore: S356, Stubbs: S312, Tocher: T260, Tonks: T520, Whytehead: W330.
Ответ на задание 3.
Ferguson: F622, Fitzgerald: F326, Hamnett: H530, Keefe: K100, Maxwell: M240, Razey: R200, Shaw: S000, Upfield: U143.
Послесловие
Задача, для решения которой использовался (и порой продолжает использоваться в наши дни) алгоритм Soundex, в общем виде называется нечётким поиском (approximate string matching, fuzzy string searching).
Умение понимать, что два языковых выражения эквивалентны, — важная часть владения человеческим языком. Это умение может проявляться на разных уровнях. Например, на уровне семантики (значений слов) и синтаксиса (связей между словами в словосочетании и предложении) носитель русского языка легко понимает, что фразы Стометровую дистанцию он проплыл кролем за 45 секунд, На сто метров кролем у него ушло 45 секунд и Стометровку он проплыл кролем за ¾ минуты (Апресян 1995: I, 12) значат одно и то же. Точно так же и на уровне букв мы легко понимаем, что Муравьёва и Муравьева — это одна и та же фамилия, а Наталия и Наталья — одно и то же имя (хотя в ситуациях, когда хочется придраться, мы можем притворно говорить что-то вроде «Ну как же, здесь написано Наталья Муравьева, а у вас в паспорте — Наталия Муравьёва»). Но автоматизировать такое базовое для нас умение — понимать эквивалентность не совпадающих точно слов и выражений — задача очень сложная.
Такие несовпадения на практике встречаются регулярно. Soundex изначально придумывался именно для сопоставления имён собственных, поскольку в начале XX века вариативность в написании имён собственных была гораздо выше, чем сейчас, — но и сейчас она не совсем сведена к нулю. Так, в книге (Lisbach, Meyer 2013: 15) приводится пример двух вариантов записи информации об одном и том же человеке — например, со слуха в колл-центре и при переписывании с документов с разделением на поля:
| Kate Suzanne Jankowiz |
| Belrive Str. 20, 65920 Frankfurt am Main (Germany) |
| Catherine | Susan | Jennifer | Yankovits-Brunner | |
| 20 | Bellerivestrasse | Frankfurt/M | 65920 | DE |
Важное достоинство Soundex, которое во многом и обеспечило его популярность, — лёгкость в реализации: в частности, для этого алгоритма не нужен словарь. Soundex упоминается в классическом пособии «Искусство программирования» Дональда Кнута (Knuth 1998: 395–396). Правда, в первом издании (Knuth 1973: 391–392) автор ещё не учёл все тонкости и предлагал одновременно выкидывать гласные, h и w; тогда, например, Chapman даёт не Chapman → Capman → Ca15a5 → C155, а Chapman → Cpmn → C155 → C15 → C150.
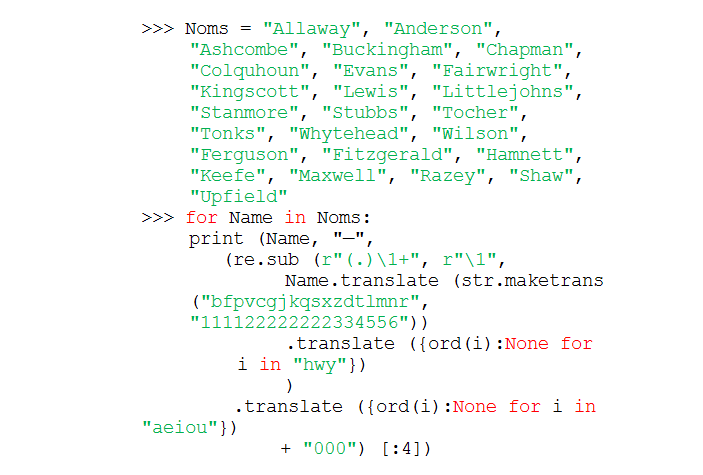
Soundex реализован в десятках языков программирования. Например, встроенная функция SOUNDEX есть в системе управления базами данных MySQL. А на Python 3 можно записать всё содержание этой задачи в нескольких строчках (автор кода — Иван Держанский):
Недостатки Soundex лежат на поверхности. Иногда этот алгоритм неспособен обнаружить сходство между очень близкими фамилиями: например, Levinson получит код L152, а Lewinson — код L525. Кроме того, Soundex плохо работает в ситуациях, когда произношение сильно расходится с написанием, что в английском языке бывает нередко. Например, шотландская фамилия Colquhoun, данная в условии, читается примерно как Кэхун, а его код Soundex C425 отражает непроизносимые l (4) и q (2). Другой вариант этой фамилии — Colhoun (вспомним капитана Кассия Колхауна из «Всадника без головы» Майн Рида) — имеет другой код: получится C450. Впрочем, в таком написании обычно произносится л (Колхун), так что разные коды в данном случае — это не так уж и плохо.
Для решения задачи нечёткого поиска нередко используются и более продвинутые алгоритмы. Это могут быть как фонетические алгоритмы наподобие Soundex (например, Metaphone), так и совсем другие подходы — например, связанные с редакционным расстоянием, задача про которое уже публиковалась на нашем сайте.
Литература:
1. Ю. Д. Апресян. Избранные труды. Т. I. // Лексическая семантика. М.: Языки русской культуры, 1995.
2. Donald Knuth. The art of computer programming. Vol. 3: Sorting and searching // Reading (Mass.), 1973.
3. Donald Knuth. The art of computer programming. Vol. 3: Sorting and searching. 2nd ed. // Reading (Mass.), 1998.
4. Bertrand Lisbach & Victoria Meyer. Linguistic identity matching // Wiesbaden: Springer, 2013.
Задача использовалась на XIII Международной олимпиаде по лингвистике в 2015 году в Благоевграде (Болгария).
-
В Википедии, кстати, немного другой алгоритм - первая буква меняется на цифру, и восстанавливается на предпоследнем шаге. Алгоритмы дают разный результат в фамилиях, начинающихся, например, на 2 согласные буквы из одной группы.
-
Спасибо! Да, в олимпиадной задаче мы не стали давать ещё этот осложняющий случай, она и так оказалась непростая. А вообще да, у тех, кто реализует Soundex строго по Кнуту, будет Lloyd = L300, а с отклонением его алгоритма Lloyd= L430. Вот тут обсуждаются всякие проблемы с разными вариантами кодирования, в том числе и Lloyd'ов призывают искать и на L300, и на L430: https://kslib.info/DocumentCenter/View/4644
-


Последние задачи






