Афалины выбирают себе «имена» так, чтобы их было лучше слышно
Долгое время разница в «диалектах» между популяциями дельфинов оценивалась по общему вокальному репертуару, и сравнительно мало внимания уделялось так называемым свистам-автографам, индивидуальным «именам», которые дельфины начинают издавать в течение первого года жизни. Чтобы понять, какие факторы обеспечивают разницу между «именами» в географически разделенных популяциях дельфинов, ученые изучили шесть групп афалин в Средиземном море, сравнив издаваемые ими свисты-автографы. Оказалось, что основное влияние на свисты оказывает не степень географической изоляции (грубо говоря, дистанция между популяциями), а экологические особенности окружающей среды и демографическая структура дельфиньих стай.
Акустические сигналы играют важную роль в общении многих видов животных, от насекомых до млекопитающих, и задействованы в самых разных аспектах жизнедеятельности, от конкуренции за ресурсы до брачных ритуалов (M. R. Wilkins et al., 2012. Evolutionary divergence in acoustic signals: causes and consequences). В частности, одни из самых «говорливых» современных млекопитающих — китообразные, — используют издаваемые ими звуки, чтобы ориентироваться в пространстве, искать пищу, избегать хищников и общаться с сородичами, причем не только членами своей группы, но и животными из соседних стай (C. Wei, 2021. Sound production and propagation in cetaceans). Логично предположить, что с помощью звуков киты должны передавать окружающим информацию о себе. И уже установлено, что у некоторых видов, таких как косатки (Orcinus orca) и кашалоты (Physeter macrocephalus), существуют региональные диалекты, причем киты-«носители» определенного диалекта предпочитают общаться друг с другом, а не с другими китами (см. О. Филатова, 2019. Язык косаток и его диалекты, V. B. Deecke et al., 2000. Dialect change in resident killer whales: implications for vocal learning and cultural transmission, L. Weilgart, H. Whitehead, 1997. Group-specific dialects and geographical variation in coda repertoire in South Pacific sperm whales).
Немалое внимание при изучении акустического общения животных уделяется различиям в сигналах между близкородственными видами или популяциями одного вида (Z. Chen, J. J. Wiens, 2020. The origins of acoustic communication in vertebrates). Предполагается, что эти различия могут быть обусловлены акустическими характеристиками среды, к которой животные вынуждены приспосабливаться (это так называемая гипотеза акустической адаптации), социальными условиями, в том числе культурными традициями (см. Культура у животных — не редкий курьез, а вездесущее явление, «Элементы», 13.04.2021), и географической изоляцией популяций (D. E. Irwin et al., 2008. Call divergence is correlated with geographic and genetic distance in greenish warblers (Phylloscopus trochiloides): a strong role for stochasticity in signal evolution?).

Кашалоты учатся общаться с сородичами в раннем детстве, после чего всю жизнь предпочитают общество тех китов, которые издают похожие звуки. Не правда ли, это похоже на человеческое общество, в котором носители одного языка предпочитают общаться друг с другом? Фото © Bryan Skerry с сайта nationalgeographic.com
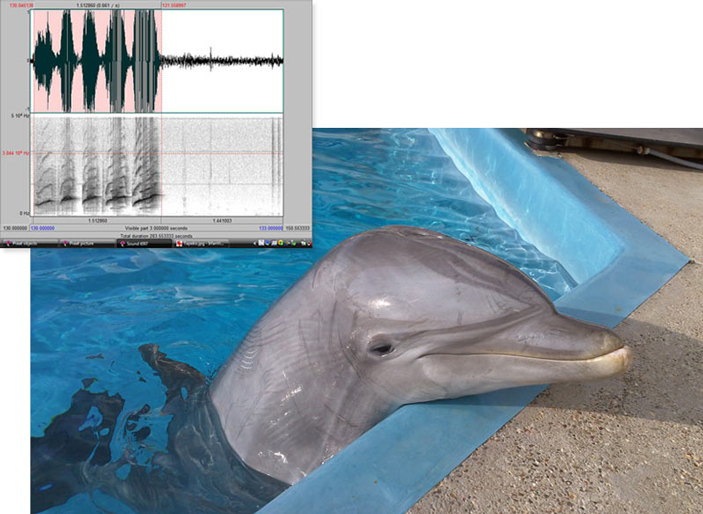
Афалины (Tursiops truncatus) используют для самоидентификации особые частотно-модулированные узкополосные сигналы, называемые «свистами-автографами» (signature whistles, см. V. M. Janik, L. S. Sayigh, 2013. Communication in bottlenose dolphins: 50 years of signature whistle research) — своеобразные «позывные», индивидуальные для каждой особи. Издавая такой свист, дельфин как бы представляется сородичам или сообщает о своем местоположении. Считается, что основные функции этих сигналов — распознавание членов группы и общение с ними, а также координирование действий внутри группы (см. Как общаются афалины?). Эти свисты отличаются характерным рисунком частотной модуляции; чаще всего дельфин использует их, когда отдаляется от группы или оказывается изолирован от нее (V. M. Janik, P. J. B. Slater, 1998. Context-specific use suggests that bottlenose dolphin signature whistles are cohesion calls). В неволе свисты-автографы в основном звучат именно в случае помещения дельфина в отдельный бассейн (V. M. Janic et al., 1994. Signature whistle variations in a bottlenosed dolphin, Tursiops truncatus), где он не может общаться с членами своей стаи, а вот у диких дельфинов они составляют 38–70% всего репертуара свистов (S. L. Watwood et al., 2005. Signature whistle use by temporarily restrained and free-swimming bottlenose dolphins, Tursiops truncatus).
Уникальный свист-автограф появляется в вокальном репертуаре афалины в течение первого года жизни и, по-видимому, формируется под влиянием свистов сородичей, окружающих дельфиненка (P. L. Tyack, L. S. Sayigh, 2010. Vocal learning in cetaceans). Свист практически не меняется в течение десятилетий (L. S. Sayigh et al., 1990. Signature whistles of free-ranging bottlenose dolphins Tursiops truncatus: stability and mother-offspring comparisons), хотя может модифицироваться, например, при смене стаи (S. L. Watwood et al., 2004. Whistle sharing in paired male bottlenose dolphins, Tursiops truncatus; чем-то похоже на ситуацию человека, переехавшего в другую страну и вынужденного адаптироваться к новой языковой среде). Известно, что существуют различия в свистах-автографах между популяциями афалин, и в последние годы число таких исследований только увеличивается. Тем не менее, до сих пор ученые не уделяли внимание факторам, влияющим на различия в свистах-автографах, — а ведь такие данные могли бы пролить свет на процесс возникновения и эволюцию этих необычных сигналов.
Дельфин издает свист-автограф, идентифицируя себя: возможно, он потерялся или был отделен от сородичей, так что теперь хочет вернуться в стаю
Чтобы понять, из каких факторов складывается уникальность свиста-автографа, ученые изучили акустическую структуру свистов (с точки зрения основных частот, частотной модуляции и продолжительности) шести географически изолированных дельфиньих популяций в Средиземном море. 188 часов акустических записей были собраны в национальном парке Порт-Крос у южных берегов Франции, на острове Сардиния и на западном берегу Италии (все эти места рассматривались как западное Средиземноморье); на островах Црес-Лошинь в Адриатическом море и в Коринфском заливе в Ионическом море (оба места рассматривались как восточное Средиземноморье); и на острове Лампедуза в Тунисском проливе (считался южным Средиземноморьем).
Всего было идентифицировано 168 уникальных свистов-автографов, после чего ученые проанализировали их на предмет вариации акустических характеристик, например, продолжительность и изменения высоты тона. Полученные данные были соотнесены с местом, где был записан свист, частью Средиземноморья, к которой это место относится, особенностями местной среды и той группы, к которой принадлежал владелец свиста.

Места записи свистов-автографов: PC, AL и FI относятся к западному Средиземноморью, LA — к южному, CL и GC — к восточному. Рисунок из обсуждаемой статьи в Scientific Reports
Оказалось, что хотя на структуру свиста влияли в той или иной степени все учитываемые факторы, в наибольшей степени уникальность свиста определялась не географической дистанцией между популяциями, а экологическими факторами, такими как тип морского дна и численность дельфиньих стай. Например, на юге Франции и на острове Лампедуза, где дно покрыто растениями (в основном это заросли посидонии), дельфины издавали более высокие и короткие свисты, в то время как на Сардинии и на западном берегу Италии, где дно илистое — более низкие и продолжительные. Авторы предположили, что это связано именно с особенностями морского дна, поскольку раньше было показано, что низкочастотные свисты (они дальше всего распространяются в морской воде, поэтому лучше всего подходят для свиста-автографа) на участках, покрытых водорослями, затухают быстрее высокочастотных (E. Quintana-Rizzo, D. A. Mann, 2006. Estimated communication range of social sounds used by bottlenose dolphins (Tursiops truncatus)), поэтому дельфинам, живущим над заросшим дном, приходится использовать иные свисты по сравнению с теми животными, которые населяют воды над илистым или песчано-илистым дном.
Наибольшее же влияние на структуру свиста оказали особенности самой популяции дельфинов, а именно ее размер. Сильнее всего различались свисты дельфинов с юга Франции, запада Италии и с острова Лампедуза, где плавают многочисленные стаи, часто меняющие свой состав, и свисты дельфинов из Коринфского залива и с острова Сардиния, где стаи сравнительно невелики. В больших популяциях структура свиста была наиболее нестабильна: вероятно, дельфины вынуждены постоянно менять свист-автограф в зависимости от окружения, чтобы их свисты не сливались со свистами других животных. В то же время в малых популяциях, где увеличивается вероятность многократных встреч с одним и тем же дельфином, свисты-автографы были более сложными и постоянными: это увеличивало вероятность правильного распознавания конкретной особи.

Зависимость характеристик свиста-автографа от региона Средиземноморья (восточный, южный, западный), в котором обитает дельфин. Основными параметрами свиста авторы сочли наименьшую частоту, начальную частоту и диапазон частот (в кГц), а также продолжительность (в секундах) и количество точек перегиба. Обратите внимание, что различия между свистами мало коррелируют с географическим расстоянием между популяциями: например, по частотам западные и восточные популяции, расположенные дальше друг от друга, отличаются меньше, чем южная, которая могла бы служить зоной «культурного обмена». Рисунок из обсуждаемой статьи в Scientific Reports
Напоследок авторы заметили, что результаты их исследования стоит воспринимать осторожно из-за некоторых методологических ограничений: например, если у стаи из Адриатического моря, состоящей из 38 дельфинов, были записаны 13 индивидуальных свистов (или 34% всех особей), то из крупных популяций западного Средиземноморья в собранной выборке представлены лишь 5% особей. Также в работе представлено ограниченное количество факторов, потенциально влияющих на изменчивость свиста-автографа: возможно, в дальнейших исследованиях стоило бы включить также звуки моторов судов, которые уже сейчас вынуждают дельфинов изменять структуру своих криков, чтобы быть услышанными в окружающем их шуме (G. La Manna et al., 2019. Influence of environmental, social and behavioural variables on the whistling of the common bottlenose dolphin (Tursiops truncatus)).
В целом проведенное исследование подтверждает «гипотезу акустической адаптации»: дельфины изменяют издаваемые ими свисты в соответствии с условиями окружающей среды, добиваясь их минимального затухания и наилучшей распознаваемости, — примерно так же, как человек, оказавшийся посреди шумной улицы, будет говорить громче и четче, чем во время прогулки в парке. Возможно, изучив свист-автограф, мы и не сможем сказать, к какой конкретно популяции принадлежит этот дельфин, но зато сумеем представить, в какой среде он рос.
Источник: G. La Manna, N. Rako-Gospić, D. S. Pace, S. Bonizzoni, L. Di Iorio, L. Polimeno, F. Perretti, F. Ronchetti, G. Giacomini, G. Pavan, G. Pedrazzi, H. Labach, G. Ceccherelli. Determinants of variability in signature whistles of the Mediterranean common bottlenose dolphin // Scientific Reports. 2022. DOI: 10.1038/s41598-022-10920-7.
Анна Новиковская
-
Исследования по передаче звуков между китами поддерживают гипотезу происхождения речи у человека.
Согласно гипотезы предтечей речи у человека должны быть вокальные композиции в виде пения песен. Мелодичные звуки в песнях использовались предками человека, по всей видимости, по той же причине, что и вокальные комбинации из свистов, которыми обмениваются киты - чтобы лучше было слышно на относительно больших расстояниях.
Дело в том, что звуки эффективнее всего генерируются элементами, у которых механическая система при их генерации вступает в резонанс. Такой излучатель генерирует мелодичные звуки. Для того, чтобы человека могли услышать максимально далеко, возможны два варианта. В первом варианте, можно издать очень короткую и мощную звуковую волну - прокукарекать. Второй вариант - сгенерировать длинную практически монохроматическую волну относительно небольшой мощности. В первом варианте есть риск надорвать голосовые связки, поэтому для длительной коммуникации он не пригоден. Второй вариант более безопасен. Модуляцию звука можно обеспечить например за счет натяжения мембран излучателя, изменения размеров акустической полости и т.д. Скорее всего так и устроен голосовой аппарат у человека (если написал неправильно - прошу поправить).
С другой стороны, необходимую для восприятия энергию при приеме звука также можно получить двумя способами. Первый способ - принять очень короткий и очень мощный сигнал. Во втором варианте с теми же параметрами по соотношению сигнал шум можно принять длинную практически монохроматическую волну небольшой мощности. Поэтому для коммуникации между людьми наиболее эффективными являются мелодичные звуки.
Сначала, по мере развития человека, эти звуки были простыми, как песни. Затем песни усложнились.-
Во втором варианте с теми же параметрами по соотношению сигнал шум можно принять длинную практически монохроматическую волну небольшой мощности. Поэтому для коммуникации между людьми наиболее эффективными являются мелодичные звуки.
Правильно ли я вас понял, что когда оперная певица на распевке тянет (то есть поёт), например, звук а-а-а-а, то ее голосовой аппарат генерирует монохроматическую волну?-
Спектр продолжительного мелодичного сигнала звука представляет собой основной тон и множество обертонов. Под практически монохроматической волной здесь необходимо понимать основной тон звуковой волны. Обертоны дают окраску звука. Основная мощность звука сосредоточена в основном тоне (в основной ноте). Например, некоторые оперные певцы могут производить звук с частотой резонанса стеклянных бакалов, разбивая при этом бакалы.
-
Например, некоторые оперные певцы могут производить звук с частотой резонанса стеклянных бакалов, разбивая при этом бакалы.
"бОкалы"
Ну да, был полста лет назад рекламный трюк у одной американской компании. Не вижу, к чему вы это тут написали (типа, а я знаю, а я слышал?).
Да это практически любой может повторить, если имеет достаточно громкий голос и музыкальный слух (в интернете полно роликов).-
Афалины (Tursiops truncatus) используют для самоидентификации особые частотно-модулированные узкополосные сигналы, называемые «свистами-автографами»
Похожие сигналы (только в другом частотном диапазоне) может формировать человек в процессе, который называют пением.
В своем комментарии пытался показать, что такие сигналы проще излучать с помощью голосового аппарата и их лучше слышно на большом удалении. Ключевой термин для понимания физики процесса - "резонанс". Физику процесса (накопление энергии во времени при резонансе, для того чтобы услышать сигнал на большом удалении) проиллюстрировал на примере бокала. В данном случае голосовые связки оперного певца являются излучателем звуковой волны. А бокал - приемником, в котором накапливается энергия звуковой волны. Момент разрушения бокала означает, что сигнал был услышан.
-
-
-
-
С другой стороны, необходимую для восприятия энергию при приеме звука также можно получить двумя способами. Первый способ - принять очень короткий и очень мощный сигнал. Во втором варианте с теми же параметрами по соотношению сигнал шум можно принять длинную практически монохроматическую волну небольшой мощности. Поэтому для коммуникации между людьми наиболее эффективными являются мелодичные звуки.
На самом деле у нас, у людей, это происходит совершенно не так.
Вот песня: во-по-ле-бе-рё-ё-зка-сто-я-я-ла-а.
У первых четырех звуков (во-по-ле-бе) тон одинаковый, то есть по-вашему одна и та же монохроматическая волна (с обертонами). Но звуки-то совершенно разные, и смысл их понятен даже ребенку.
А если просто напеть мелодию, без слов: вот тогда будет четыре чистые монохроматических волны (с обертонами), но смысл будет уже утерян.
Так что ваша монохроматическая волна с бокалами сгубила вашу "гипотезу" на корню.
Попробуйте заново сформулировать, но только без бокалов и без монохроматической волны. -
Не оч понял, как так у Вас выходит, что сигнал в двух Ваших вариантах разный по громкости (ведь именно громкость
звука Вы подразумеваете под словом "мощный", я верно понял?), а соотношение сигнал/шум при этом одинаковое. Логично б было для соблюдения этого условия во втором варианте шум... э... приглушить как-то)
Кроме того, Вош образ "короткого мощного сигнала" в идеале прекрасно совпадает с ударом или хлопкОм, и потому совершенно не нагрузит ничьи голосовые связки. Зачем рвать связки для короткого звука, когда можно оч громко хлопнуть в ладоши?
А что касается пения - так этот процесс от крика отличается мало. Можно сказать, вовсе никак. Не напевание, а именно пение, оперное - когда вокалист поёт форте - вчуже страшно стать может, если вблизи. Зато на галерке хорошо слыхать)
и связки певцы не зря так берегут - именно потому, что они у них работают на полную катушку, по максимуму, это ошибка думать, что профессиональное пение - это то, что мама дитю напевает. Такую - мамину колыбельную - "длинную монохроматическую волну небольшой мощности" кто услышит? Как сказал классик: "разве что жена. Да и то, не на базаре, а близко"))-
"Не оч понял, как так у Вас выходит, что сигнал в двух Ваших вариантах разный по громкости (ведь именно громкость звука Вы подразумеваете под словом "мощный", я верно понял?), а соотношение сигнал/шум при этом одинаковое. Логично б было для соблюдения этого условия во втором варианте шум... э... приглушить как-то)"
Чем громче звук, тем больше кратковременная мощность его звуковых волн (т.е.. мгновенная мощность). Например, более мощный динамик способен издавать более громкий звук.
В данном случае под шумом следует понимать внешний шум. Хотя есть и внутренний шум, когда в ухе шумит. Мы подразумеваем, что внешний шум имеет практически постоянную мощность. Например шум на улице, или шум ветра в кронах деревьев в лесу. Этот шум нельзя приглушить. Обычно внешний шум имет широкий спектр звуковых водн.
Так вот, если сформировать звуковую волну с узким спектральным диапазоном, то эту волну можно эффективно отфильтровать от шума с помощью узкополосного фильтра.
Такой фильтр, по моему, имеется в конструкции слухового аппрата у человека, а также алгоритм фильтрации реализуется с помощью контуров нейронной сети головного мозга. В результате чего, несмотря на то, что мощность звукового сигнала, принимаемого ухом, будет менше, чем мощность внешнего шума, этот сигнал можно услышать.
"Кроме того, Ваш образ "короткого мощного сигнала" в идеале прекрасно совпадает с ударом или хлопкОм, и потому совершенно не нагрузит ничьи голосовые связки. Зачем рвать связки для короткого звука, когда можно оч громко хлопнуть в ладоши?"
Вы можете экспериментально это проверить. Когда потеряетесь в лесу собирая грибы, попробуйте хлопать в ладоши, заместо того, что издавать звук А...У...
По последнему абзацу отвечу немного позже.-
Ну, если про заблужденияя в лесу - это не о громкости (по-Вашему - мощности) звука, а
Во-первых, однозначно показать нужно, что изданий Вами звук именно человечьего происхождения, а не естественно-природного. Если в лесу громко стучать, то не всякий услышавший сообразит, что это искусственный стук. Но достаточно начать стучать/хлопать ритмично - любой и сразу поймёт, что эти хлопки/стуки - неспроста!)
И вот Вам - опа! - и голосовые связки не пригодились)
Но этого недостаточно, чтоб помогли выбраться, и потому
Во-вторых, должно быть ясно, что издающий звуки ждёт помощи. Если просто орать хоть короткими гавканьями, хоть руладами , песню даже пой - хоть и услышит кто, но на помощь не придёт. А если звать на помощь, или даже стучать "сос" азбукой Морзе - вероятность, что услышавший придёт на помощь скачком возрастает до единицы.
Без узкополосных фильтров.
Согласны?
-
-


Вот в этом абзаце -
"низкочастотные свисты (они дальше всего распространяются в морской воде...) на участках, покрытых водорослями, затухают быстрее высокочастотных"
- что-то тут непонятное вышло.
Мне таки кажется, что либо то, либо другое.
Либо "дальше всего распространяются"
Либо "затухают быстрее"
Ведь и там и там звук идет в морской воде. При чем тут дно?
Другое дело, если б речь шла об отражении звуковой волны от дна. Да и тогда малопонятно, что хуже отражает - ил или растения. Зато очевидно, что скала и песчаное дно отразят лучше.
Однако,повторюсь, об отраженном звуке нигде в статье речи нет...
Как-то надо бы тут то ли исправить, то ли разъяснить...
Согласны?
-
Разъясняю: низкочастотные свисты в целом распространяются в воде дальше высокочастотных, но на участках, где дно покрыто водорослями, затухают быстрее. Ссылки на статьи в тексте есть.
-
что ссылки на статью есть - это оч хорошо.
Я о другом: распространение звука по воде и затухание звука в зависимости от стенок сосуда - просто совсем не связанные вещи.
Распространение по воде упругих колебаний этой самой воды никоим образом не может быть изменено покрытием дна.
Именно потому, что фронт упругой этой этой волны идет по воде.
А не по дну.
И зависит его ход от свойств воды.
А не дна.
а вот затухание, похоже, обеспечивается "удачным" взаимодействием волн звука с отражениями его от дна.
А при первом прочтении мне показалось, что эти два факта рядом не просто так. Теперь понимаю - соседство случайно, инфа о распространения частот в воде "вообще" - просто случайно упомянута, то, что называется "к слову пришлась"...
Так что - каюсь, зря пыхтел, простите)
-
Киты и дельфины
-
 06.06.2024Пережив китобойный промысел, горбатые киты столкнулись с глобальным потеплениемОльга Титова • Новости науки
06.06.2024Пережив китобойный промысел, горбатые киты столкнулись с глобальным потеплениемОльга Титова • Новости науки
-
 19.02.2023Карликовый кашалотАнна Новиковская • Картинки дня
19.02.2023Карликовый кашалотАнна Новиковская • Картинки дня
-
 15.06.2022Афалины выбирают себе «имена» так, чтобы их было лучше слышноАнна Новиковская • Новости науки
15.06.2022Афалины выбирают себе «имена» так, чтобы их было лучше слышноАнна Новиковская • Новости науки
-
 13.06.2022Китовый следАйк Акопян • Задачи
13.06.2022Китовый следАйк Акопян • Задачи
-
 10.07.2020Лебединые песни китовАнтон Нелихов • Рецензии
10.07.2020Лебединые песни китовАнтон Нелихов • Рецензии
-
 26.06.2020«Киты и дельфины». Главы из книгиОльга Филатова • Книжный клуб • Главы
26.06.2020«Киты и дельфины». Главы из книгиОльга Филатова • Книжный клуб • Главы
-
24.04.2020«Наблюдая за китами». Глава из книгиНик Пайенсон • Книжный клуб • Главы
-
 20.03.2020Киты со шрамамиОльга Филатова • Картинки дня
20.03.2020Киты со шрамамиОльга Филатова • Картинки дня
-
 11.03.2020Беззубый предок усатых китовЯрослав Попов • Библиотека • «Природа» №12, 2018
11.03.2020Беззубый предок усатых китовЯрослав Попов • Библиотека • «Природа» №12, 2018
-
 19.02.2020Гладкий китОльга Филатова • Картинки дня
19.02.2020Гладкий китОльга Филатова • Картинки дня
Последние новости











Дельфины помнят «имена» друг друга в течение десятилетий. На фотографии изображен дельфин по кличке Кай из Техасского океанариума (Texas State Aquarium), а на врезке — его свист-автограф, которым он представляется при встрече с незнакомыми дельфинами или сообщает о себе, отбившись от семьи. Фото © Jason Bruck с сайта science.org