«Нормальность» и «критичность»
Если взять сотню взрослых самцов индийских слонов и измерить их рост и вес, а потом построить соответствующие гистограммы, то они получатся примерно такими, как показано на рис. 1. И это вполне логично, ведь очень трудно найти взрослого слона, который бы весил очень мало или очень много или был бы очень низким или очень высоким. То есть значения роста и веса будут кучковаться вокруг неких средних значений. Более того, с увеличением размера выборки гистограммы будут все ближе к так называемой колоколообразной кривой, характерной для нормального (гауссова) распределения.

Похожим образом будет выглядеть, скажем, распределение весов новорожденных (S. Choukem et al., 2016 High birth weight in a suburban hospital in Cameroon: an analysis of the clinical cut-off, prevalence, predictors and adverse outcomes), распределение людей по оценкам на экзамене (Visualize SAT scores in North Carolina), распределение машин по их скоростям на шоссе (D. Helbing, B. Tilch, 2009. A power law for the duration of high-flow states and its interpretation from a heterogeneous traffic flow perspective) и распределения многих других совокупностей однотипных величин, каждая из которых определяется вкладом большого количества независимых друг от друга параметров (например, на вес и размер слона влияет состояние его здоровья, скорость метаболизма, количество доступной пищи, генетика, климат и многое другое). В рамках теории вероятностей доказываются так называемые центральные предельные теоремы, описывающие разные условия, при которых с ростом выборки получается нормальное распределение.
Задача 1
Рассмотрите простейший случай — подкидывание монетки. Здесь параметром служит исход подбрасывания, который с равной вероятностью может принять любое из двух значений. Если подкидывать одновременно \(n\) монет со сторонами, на которых написаны числа 1 и 0, то как будет распределена сумма всех выпавших чисел? Иными словами, какова вероятность, что сумма чисел, выпавших на всех \(n\) монетах, равна \(k\)? Что происходит с ростом \(n\)?
Хотя нормальное распределение встречается сплошь и рядом, мир был бы абсолютно неузнаваем, если бы вообще все было распределено нормально. На рис. 2 показаны примеры распределений, которые далеки от нормального. Все они, на самом деле, имеют общую черту: они хорошо описываются степенным законом. И это лишь малая часть из огромного набора примеров из физики, экономики, антропологии, биологии и других областей, когда величины распределены таким образом (а помимо нормального и степенного распределений в статистике есть еще много других).

Рис. 2. Распределение различных величин по их частоте. Например, на графике (м) по горизонтальной оси отложено количество людей, живущих в городе, а по вертикальной оси — количество городов с данным населением. Все эти распределения хорошо описываются степенным законом. Графики из статьи M. Newman, 2005. Power laws, Pareto distributions and Zipf's law
О том, что распределение многих величин подчиняется степенному закону, было известно уже давно. К примеру, в экономике в конце XIX — начале XX века итальянским социологом Вильфредо Парето был популяризирован закон «80–20», согласно которому 80% богатств страны (Парето изучал Италию) владело всего 20% населения (см. Распределение Парето). Подобные наблюдения были сделаны в первой половине XX века и в лингвистике: оказывается, если подсчитать встречаемость слов в достаточно большом тексте, то получится, что на очень небольшое количество слов (как правило, это служебные части речи) приходится большинство вхождений (см. Закон Ципфа). Например, в английском на слова «the», «of» и «and» приходятся доли в среднем 5%, 3,5% и 2,7%, соответственно; а всего лишь 135 слов «занимают» более половины от всех слов в большом тексте.
Задача 2
Объясните, откуда могут возникать степенные распределения величин вроде показанных на рис. 2? Для примера рассмотрите распределение количества жителей в городах. В чем здесь ключевое отличие от задачи 1?
Подсказка
На самом деле единого ответа, объясняющего, почему возникают степенные распределения, нет — причины зависят от конкретного случая. Но одним из ключевых отличий от нормального распределения в подобных системах является отсутствие характерного масштаба. Иными словами, форма распределения величины \(g(x)\) не должна меняться, если вы рассмотрите ее на другом масштабе, то есть замените \(x\) на \(kx\). Скажем, если вы измеряете размеры лунных кратеров не в км, а в см, или включаете в выборку только кратеры из определенной области (а не со всей Луны), то форма распределения не должна измениться.
Решение
Пусть монетка, на сторонах которой написаны 0 и 1, подкинута \(n\) раз. Очевидно, что максимальная сумма чисел, которую можно получить в , равна \(n\), — для этого нужно, чтобы на всех монетках выпала единица. Минимальная сумма равна 0, и достигается она, если на всех монетках выпал ноль. Каждый из этих исходов реализуется с вероятностью \((1/2)^n\), так как есть только одна комбинация результатов выпадения отдельных монет, которая дает общую сумму 0 или \(n\).
Также ясно, что для любого другого возможного значения суммы \(m\) (\(0<m<n\)) комбинаций больше, — а значит, больше и вероятность выпадения. Например, если \(m=1\), то нужная сумма получается, когда ровно на одной из монет выпадет 1. Эта монета может быть любой из \(n\) штук, то есть всего получается \(n\) подходящих комбинаций, а поскольку вероятность выпадения каждой из них по-прежнему равна \((1/2)^n\), то полная вероятность того, что на всех монетах выпадет сумма \(m=1\), равна \(p(m=1)=n(1/2)^n\).
Аналогичные рассуждения работают и для других значений \(m\): сумма, выпавшая на всех монетках, — это просто количество единиц, а значит надо подсчитать число способов, которыми можно выбрать \(m\) монет из общего набора в \(n\) монет. В комбинаторике это число хорошо известно (точнее, известно, как отвечать на такой вопрос при любых \(m\) и \(n\)): оно равно биномиальному коэффициенту \( C_n^m=\frac{n!}{m!(n-m)!}\).
Значит, \(p(m)=C_n^m\left(\frac{1}{2}\right)^n\).
В качестве упражнения покажите, что сумма всех \(p(m)\) при \(m=0,~...,~n\) равна, как и следует ожидать, единице.
Нам интересно, как выглядит зависимость \(p(m)\) от \(m\), когда \(n\gg 1\).
Удобно обозначить \(x=m/n\) (тогда величина \(x\) будет меняться от 0 до 1). Воспользуемся формулой Стирлинга, которая при больших \(n\) позволяет приближенно выразить факториал через экспоненту: \(n!\approx \sqrt{2\pi n}(n/e)^n\). Тогда, с учетом того, что \(m=nx\), наша формула запишется следующим образом:
\[ p(x)\approx\frac{1}{\sqrt{2\pi}}\frac{n^{n+1/2}}{(nx)^{nx-1/2}(n-nx)^{n(x-1)-1/2}}\left(\frac{1}{2}\right)^n.\]Постоянный коэффициент \(\sqrt{2\pi}\) нас не интересует. Также проигнорируем \(1/2\) в показателе степени, так как \(n> nx\gg 1>1/2\). Число \(n\) можно вывести из обеих скобок в знаменателе и сократить с числителем. В итоге получится следующее выражение:
\[ p(x)\propto \left[2x^x(1-x)^{1-x}\right]^{-n}. \]При больших значениях \(n\) нас интересуют значения \(x\approx 1/2\), поскольку, как мы видели выше, при \(x\to 0\) и \(x\to 1\) вероятность стремится к нулю. Обозначим \(x=1/2 + u\) — это позволяет сдвинуть «область интереса» к нулю: теперь надо исследовать область \(u\approx 0\). Перепишем полученное приближение для \(p(x)\), пользуясь тождеством \(e^{-n\ln{a}} = a^{-n}\):
\[ p(u)\propto\exp{\left[-n\left\{\ln{2}+\left(\frac{1}{2}+u\right)\ln{\left(\frac{1}{2}+u\right)}+\left(\frac{1}{2}-u\right)\ln{\left(\frac{1}{2}-u\right)}\right\}\right]}.\]Пользуясь свойствами логарифма, выражение в фигурных скобках можно упростить:
\[ p(u)\propto \exp{\left[-n\left\{\frac{1}{2}\ln{(1-4u^2)}+u\ln{\left(1+2u\right)}+u\ln{\left(1-2u\right)}\right\}\right]}.\]Так как нас интересует область \(u\approx 0\), логарифм можно приблизить с помощью формулы \(\ln{\left(1+a\right)}\approx a\), которая работает для малых \(a\). Если это проделать, а потом заменить \(u\) обратно на \(x\), то в итоге получится:
\[ p(x)\propto \exp\left[-2n(x-1/2)^2\right], \]что с точностью до постоянного множителя как раз соответствует нормальному распределению (при \(x\approx 1/2\)), плотность вероятности которого в общем случае задается формулой \(\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\).
В нашем случае \(\sigma=1/\sqrt{2n}\) — это стандартное отклонение. По сути, оно показывает, насколько сильно могут случайные значения отклоняться от среднего, которым здесь является \(\mu=1/2\). Чем отклонение меньше (а оно уменьшается с ростом \(n\)), тем «ближе» часто выпадающие значения суммы будут группироваться к \(x=1/2\) (что соответствует \(m=n/2\)) и тем более точным будет наше приближение (рис. 3).

Рис. 3. Распределение вероятностей для значений суммы чисел, выпадающих при подкидывании \(n\) монеток. При больших \(n\) распределение близко к нормальному со средним \(n/2\) и стандартным отклонением \(1/\sqrt{2n}\)
Обратите внимание, что в случае с подкидыванием монеток вероятность каждого из отдельных исходов (выпадение 1 или 0 на отдельной монете) одинакова, то есть распределение однородное. Однако на выходе мы получаем нормальное распределение! Аналогичные рассуждения (и вычисления) работают и в ситуациях с большим количеством возможных состояний (например, вместо монет можно бросать игральные кости и подсчитывать сумму получившихся чисел). Более того, этот результат можно обобщить и на более сложные неоднородные распределения входных состояний: на выходе всегда получается нормальное распределение (если все, что нас интересует — это сумма каких-то параметров).
Следуя этой логике, легко понять, почему многие величины (имеющие случайную природу) в нашем мире распределены нормально. К примеру, на то, с какой скоростью конкретный водитель едет по дороге, влияет огромное количество случайных факторов: разрешенная скорость движения, загруженность дороги, ее качество, погодные условия, настроение и т. д. Каждый из этих факторов имеет абсолютно непредсказуемое распределение возможных состояний, но в сумме для большого количества машин все эти факторы складываются в результат — скорости распределены нормально.
Как уже говорилось в условии, в теории вероятностей этот результат называется центральной предельной теоремой. Из него следует еще один интересный вывод, который проиллюстрируем все тем же примером с подкидыванием монетки. Чем больше подкидываний (\(n\)), тем (в среднем) меньше отклонение значения суммы от среднего (\(n/2\)). Это означает, что количество выпавших нулей и единиц при большом числе подкидываний будет примерно одинаковым, а разница будет уменьшаться как \(\sqrt{n}\). Это наблюдение можно использовать, если требуется проверить «честность» монетки с помощью большого числа подкидываний. Правда, чтобы увеличить точность ответа в \(k\) раз (то есть чтобы сократить случайный разброс в \(k\) раз), нужно увеличить число попыток в \(k^2\) раз. Оно же известно в инженерии. Представьте, что с помощью антенны надо зарегистрировать некий очень шумный повторяющийся сигнал, усредняя данные по нескольким измерениям. После 10 повторений уровень «полезного» сигнала будет примерно равен уровню фонового шума. Но чтобы снизить уровень шума хотя бы до 10%, потребуется увеличить количество сигналов примерно до 1000 — в 100 раз!
К решению задачи 2 можно подойти с разных сторон. Рассмотрим, к примеру, распределение лунных кратеров по размеру, которое мы обозначим \(f(x)\) (\(x\) — это размер кратера). Какими свойствами обладает это распределение? С физической точки зрения можно предположить, что здесь нет выделенного масштаба (в отличие от нормального распределения, где характерный масштаб задается средним). Иными словами, форма распределения \(f(x)\) не должна меняться, если мы рассматриваем кратеры размером от 100 м то 1 км, или от 1 до 10 м. Как это записать математически?
Возьмем распределение \(f(x)\) и произведем замену \(x\to kx\). Утверждение об отсутствии характерного масштаба означает, что распределение меняется лишь на некий коэффициент, который зависит от \(k\), но не меняет форму графика функции: \(f(kx) = A(k) f(x)\). Для простоты и без потери общности положим \(f(1) = 1\) (то есть просто отнормируем распределение). Тогда, подставив \(x=1\), получим \(f(k) = A(k)\), то есть зависимость \(A(k)\) от \(k\) такая же, как зависимость \(f(x)\) от \(x\). Это, в частности, означает, что \(f(xy) = f(x) f(y)\). Взяв производную этого выражения по \(y\) и подставив \(y=1\), получим:
\[ x f'(x)=f(x)f'(1), \]где \(f'(1)\) — некое число, которое мы обозначим \(-\tau\), равное производной \(f(x)\) в точке \(x=1\). В итоге мы получили дифференциальное уравнение на функцию \(f(x)\). Чтобы его решить, достаточно сначала перераспределить члены:
\[ \left(\ln{f(x)}\right)'=-\tau \frac{1}{x}, \]а затем проинтегрировать обе части (воспользовавшись тем, что \(f(1) = 1\) для нахождения константы интегрирования):
\[ \ln{f(x)} = -\tau \ln{x}. \]Окончательно получим \(f(x) = x^{-\tau}\). Вот и появился степенной закон!
Переформулируем этот вывод, полученный с помощью математических манипуляций: если некоторая случайная величина не имеет характерного выделенного масштаба (то есть если форма ее распределения не зависит от величины), то эта величина распределена по степенному закону.
Давайте теперь исследуем несколько иной процесс, который также приводит к степенному закону распределения, и рассмотрим распределение людей по городам: пусть \(x\) — население города, а \(f(x)\) — число городов с данным населением. Смоделируем развитие городов следующим образом. Допустим, изначально есть несколько городов с одинаковым населением. Со временем население городов будет меняться (происходит естественный рост численности жителей, кто-то переезжает и т. п.). Поначалу все города будут иметь примерно одинаковый темп роста, однако со временем, при возникновении (по каким-либо причинам) малейших отклонений от среднего появится разница. Логично считать, что более населенные города успешнее, поэтому люди будут более охотно в них переезжать. Естественный прирост в них тоже будет выше. Таким образом, более населенные города будут расти пропорционально быстрее, чем менее населенные, и отрыв со временем будет увеличиваться. Кстати, аналогичные рассуждения можно провести и с распределением богатства: несмотря на то, что общее благосостояние человечества растет, богачи богатеют быстрее бедных, поэтому имущественное расслоение (в отсутствие какой-либо внешней регуляции) со временем только увеличивается.
Какое распределение населения мы получим в итоге? Население города зависит от многих факторов, поэтому случайную величину \(x\), можно представить как произведение случайных параметров, отвечающих этим факторам: \(x=r_1 \cdot r_2 \cdot ... \cdot r_n\). Оказывается, в этой модели можно воспользоваться уже полученным для нормального распределения результатом. Чтобы свети нынешнюю задачу к уже решенной, прологарифмируем это равенство (и воспользуемся тем, что \(\ln{ab} = \ln{a}+\ln{b}\)):
\[ \ln{x}=\ln{r_1}+\ln{r_2}+...+\ln{r_n}.\]Таким образом, величина \(\ln{x}\) является суммой случайных чисел, а значит должна быть распределена нормально:
\[ f(\ln{x})\propto\exp{\left[-\frac{(\ln{x}-\mu)^2}{2\sigma^2}\right]}, \]где числа \(\mu\) и \(\sigma\) (среднее и стандартное отклонение) зависят от конкретных значений величин \(r_i\) (характер этой зависимости нас пока не интересует).
Чтобы из этого получить распределение \(\tilde{f}(x)\), нужно вспомнить, что вообще такое функция распределения \(f(x)\). А смысл ее в следующем. Если некоторая случайная величина \(x\) задана распределением \(f(x)\), то вероятность того, что эта случайная величина принимает значение из интервала \((x_0-\Delta x/2,~x_0+\Delta x/2)\) равна \(p(x\approx x_0) = f(x_0)\Delta x\). Обычно \(\Delta x\) опускают, и считают, что термины «вероятность» и «распределение» имеют один и тот же смысл.
В нашем случае обозначим \(\ln{x}=u\). Тогда вероятность \(p(u\approx u_0)=f(u_0)\Delta u\). С другой стороны, \(p(x\approx x_0)=\tilde{f}(x_0)\Delta x\), где \(\ln{x_0}=u_0\). Эти вероятности должны быть одинаковы, так как замена переменных не должна никак влиять на физическую действительность. Значит:
\[ \tilde{f}(x)=f(u)\frac{\Delta u}{\Delta x}=f(\ln{x})\frac{d\ln{x}}{dx}=\frac{1}{x}f(\ln{x}). \]Заметим, что логарифм — довольно медленно изменяющаяся функция. Поэтому при \(\ln{x}\approx \mu\) изменением значения экспоненты можно пренебречь, имея таким образом:
\[ \tilde{f}(x)\propto x^{-1}. \]Послесловие
Еще одной иллюстрацией того, как степенные законы возникают в природе, служит следующая модельная задача. Представьте квадрат \(n\times n\) разбитый на единичные клетки. Каждая клетка может быть окрашена в черный или в белый цвет. Пусть доля белых квадратов равна \(p\) — будем называть это число заполнением плоскости. Если \(p=0\), то все клетки черные, если \(p=1\), то, наоборот, все клетки белые. Будем считать, что цвет каждой клетки случаен и, в частности, не зависит от цвета соседних клеток. Вопрос, который нас здесь интересует: как устроено распределение связных областей из белых клеток в зависимости от размера области? Одной связной областью мы считаем группу клеток одного цвета, которые можно обойти «ходом ладьи» (иными словами, клетки прилегают к другим клеткам области по стороне, а не через угол; рис. 4). Итак, как устроена функция \(f(x)\), равная количеству белых областей, площадь которых равна \(x\) клеток?

Рис. 4. Квадрат \(10\times 10\) с заполнением \(p=0{,}24\). Указан размер каждой белой области
При малых \(p\) белые области будут относительно равномерно распределены по квадрату, причем их размер будет в среднем достаточно маленьким — близким к 1. Это означает, что функция \(f(x)\) будет сконцентрирована в области \(x\approx 1\). С другой стороны, при достаточно больших \(p\) мы, скорее всего, увидим одну или несколько очень больших белых областей и какое-то количество маленьких белых областей, отделенных от больших белых областей черными «полями». На рис. 5 показано, как меняется распределение \(f(x)\) для квадрата \(10000\times 10000\) при изменении \(p\) от 0,1 до 0,9.
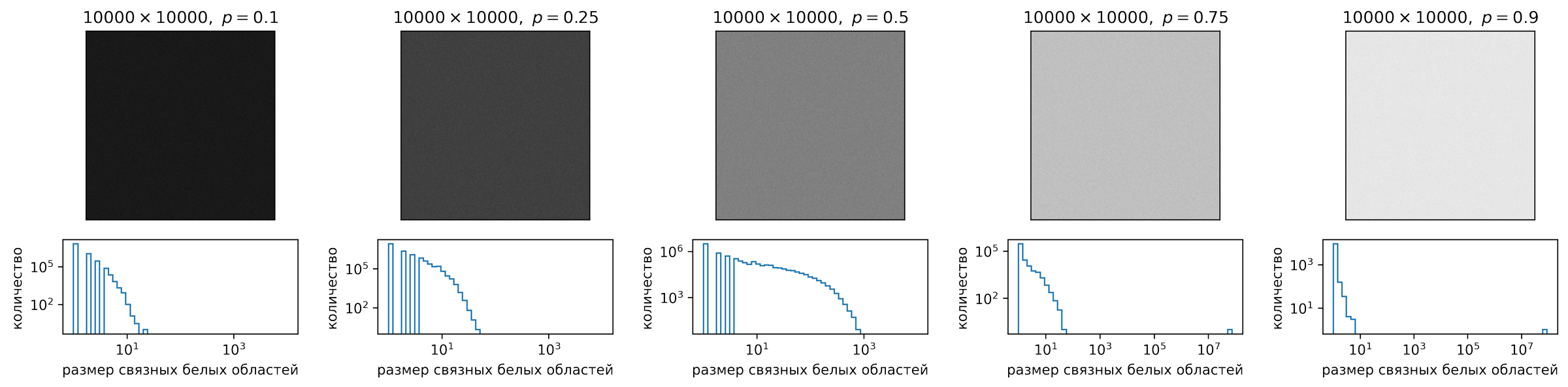
Рис. 5. Распределение размеров связных белых областей для различных значений заполнения \(p\)
Из этого рисунка видно, что где-то между 0 и 0,5 поведение «раскраски» меняется: при \(p\approx 0{,}5\) размеры областей имеют степенное распределение в достаточно широком диапазоне значений \(x\), тогда как при малых и при больших \(p\) размер областей сконцентрирован преимущественно вблизи \(x=1\) с малочисленными «выбросами» на больших \(x\) для \(p\), близких к 1.
Эта «клетчатая» модель позволяет рассмотреть довольно важный и сложный процесс перколяции — распространения жидкости в пористых материалах. Представьте, что вы пытаетесь перебраться с левой стороны случайно сгенерированного черно-белого клетчатого квадрата на правую, но ходить вам разрешено только по белым клеткам, перешагивая через сторону (перепрыгивать черные клетки нельзя). При малом заполнении \(p\) вероятность того, что белые клетки смогут соединить противоположные стороны квадрата («берега»), очень мала. Но при большом заполнении \(p\approx 1\) ясно, что почти наверняка найдется достаточно большая связная область, соединяющая два берега. Получается, что такая система меняет природу своего поведения при изменении параметра \(p\) от 0 до 1: доля квадратов, которые можно пересечь по белым клеткам (она же — вероятность, что случайно раскрашенный квадрат можно будет пересечь), вырастает от 0 до 1. Причем можно строго показать, что чем больше размер квадрата, тем более резким получается этот переход!
Подобные модели широко используют в физике твердого тела для математического описания процессов фазового перехода в веществе, когда из-за изменения некоторого внешнего параметра, например, температуры, поведение вещества меняется скачкообразно (см. Теория перколяции, а также статью филдсовского лауреата Станислава Смирнова О современной математике и ее преподавании).
Например, в статистической физике популярна так называемая модель Изинга, где вместо двумерного квадрата с черно-белыми клетками рассматриваются ферромагнитные атомы в кристаллической решетке. У ферромагнитных атомов есть ненулевое магнитное поле, направление которого зависит от направления спина. Спин каждого из атомов в решетке в общем случае зависит от магнитного поля соседних атомов: спины стремятся быть «сонаправленными», чтобы минимизировать полную энергию. Однако, что интересно, это поведение зависит от температуры! Если температура достаточно мала (по аналогии с \(p\)), то случайные колебания атомов слишком слабы, и все спины действительно оказываются сонаправленными друг другу (по аналогии — почти все клетки в квадрате черные). В этом случае полный магнитный момент вещества максимален, и это можно явно измерить на макроскопическом масштабе! Если же температура достаточно высокая, то атомы не замечают магнитное поле соседей, и их спины будут направлены совершенно произвольно, а полный магнитный момент будет равняться нулю (происходит фазовый переход, как при приближении \(p\) к 0,5, рис. 6).

Рис. 6. Полный магнитный момент ферромагнитного вещества в зависимости от температуры. Рисунок с сайта farside.ph.utexas.edu
В теории твердого тела это переходное значение называют температурой Кюри (\(T_c\)), а состояние вещества при такой температуре называют критическим. Как мы убедились выше, в критическом состоянии многие статистические свойства вещества (размеры кластеров и т. д.) имеют именно степенное распределение (что достаточно логично, если вспомнить, что в точке Кюри у системы нет выделенного масштаба).
Однако возникает интересный вопрос. Допустим, что у многих систем в природе действительно есть некоторый внешний параметр (например, температура), который регулирует переход из обычного состояния в критическое. Но почему многие физические системы способны долго существовать при критических значениях параметра? Вспомните рис. 2 — из этих графиков ясно видно, что, скажем, распределения интенсивностей землетрясений или мощностей солнечных вспышек явно находятся в критическом состоянии постоянно. Что же заставляет эти физические системы находиться в постоянном равновесии в точке Кюри?
Для объяснения этого феномена снова прибегнем к аналогии и воспользуемся моделью с клетчатым квадратом (проводить такую аналогию на нашем уровне строгости вполне можно, поскольку, как вы уже могли убедиться, обсуждаемые физические системы ведут себя довольно сходно). Только теперь квадрат будет символизировать участок земли, белая клетка будет соответствовать наличию дерева, а черная — его отсутствию. Посмотрим на эту модель в динамике. Пусть в пустых клетка с некоторой вероятностью будут возникать новые деревья, а в клетках с деревьями с некоторой вероятностью могут вспыхивать пожары, которые распространяются по соседним (через сторону или угол клетки) деревьям, «убивая» их. Нас, опять же, будет интересовать распределение размеров связных областей (лесов) на этом участке, либо, например, распределение интенсивностей пожаров (сколько деревьев было уничтожено каждым из таких пожаров).
Симуляция этого процесса показана на рис. 7. Из нее видно, что большие леса достаточно быстро сгорают, однако такие большие пожары останавливаются, когда деревьев в лесу не остается. Маленькие же леса сгорают достаточно редко, так как вероятность пожара в них очень мала.

Рис. 7. Симуляция распространения пожаров на участке земли с постоянным рождением деревьев. Анимация с сайта scipython.com
Таким образом, при малых значениях заполненности (\(p\approx 0\)) система будет стремиться увеличить \(p\) (рождается много деревьев, но в основном они образуют маленькие «рощи»), тогда как при большой заполненности (\(p\approx 1\)) крупные леса (которые почти неизбежно будут возникать) быстро сгорают и \(p\) уменьшается. Значит, эта система будет «болтаться» вокруг какого-то промежуточного состояния, которое как раз и той самой критической точкой!
Похожий с точки зрения рассмотренной модели процесс, скорее всего, лежит в основе солнечных вспышек: замагниченные области в солнечной короне вырастают и сливаются из-за магнитогидродинамического динамо вблизи поверхности Солнца, и случайным образом «взрываются», пересоединяясь (см. задачу Магнитное пересоединение). Причем, как и в случае с пожарами, чем больше размер области, тем больше вероятность такой вспышки.
Этот процесс в математике и физике называют самоорганизуемой критичностью. Она была впервые рассмотрена в классической статье 1987 года Self-organized criticality: An explanation of the 1/f noise, где была рассмотрена модель песчаной кучи. В рамках этой модели песок сыпется на поверхность уже сформированной песчаной горки. Время от времени на горке происходят «лавины» различного масштаба, из-за которых песок перераспределяется. Можно показать, что такая система находится в постоянном критическом состоянии, а масштабы лавин, как неудивительно, распределены по степенному закону.




Рис. 1.