Сходство между неродственными языками коррелирует с генетической близостью их носителей

Лингвисты давно заметили, что языки контактирующих друг с другом народов могут сближаться грамматически, лексически и фонетически, но лишь недавно появились первые масштабные доказательства этого эффекта, основанные на генетических методах. Новое исследование, опубликованное в журнале Science Advances, оценивает вклад географической близости в глобальном масштабе. И хотя этот вклад оказался не таким большим (порядка нескольких процентов «добавочной» вероятности, что языки будут более похожи), результаты исследования заставляют пересмотреть некоторые привычные представления о механизмах сближения и эволюции языков.
Носителя русского языка, приехавшего в Болгарию, поражают особенности языка этой страны: имея письменность на кириллице и немного архаичную, но понятную лексику, болгарский резко отличается в грамматическом плане. В отличие от других славянских языков, в нем нет падежей (так же как и в английском) — и отношения между словами выражаются с помощью предлогов (рис. 1). Нет в болгарском и инфинитивов — безличных начальных форм глагола, так что конструкции типа «хочу написать письмо» выражаются через оборот цели: искам да напиша писмо (буквально «хочу, чтобы напишу письмо»). Грамматика настолько выбивается из общей картины сходства, что невольно задаешься вопросом: как такое получилось?
Лингвистам ответ давно известен: у румын и греков — соответственно северных и южных соседей болгар — такая же ситуация. Исчезновение падежей (греческий язык — исключение, там осталось три из древнегреческих пяти падежей) и инфинитивов, плюс некоторые другие грамматические особенности, делают эти языки грамматически очень похожими. Сходство между ними этим не ограничивается и распространяется на фонетику, глагольное управление и роль предлогов, а также особенности образования глагольных форм. Эти изменения затрагивают не только болгарский, греческий и румынский языки, но также албанский, сербский, аромунский и даже цыганский. Вместе они входят в балканский языковой союз — совокупность индоевропейских языков абсолютно разных ветвей и с разной лексикой, конвергентно развивших общие черты в результате близкого контакта.
Балканский языковой союз — это лишь самый известный из языковых союзов, всего их описано порядка десяти. Это максимально наглядный пример, показывающий, как близкий контакт языков может вести не только к заимствованию слов, но и к взаимопроникновению их типологических черт — фонетических, синтаксических и морфологических особенностей. На материале других языков можно иногда отследить заимствование отдельных черт, без формирования полномасштабного языкового союза. Например, кликсы — щелкающие согласные — уникальны для африканских койсанских языков, но под влиянием географической близости они проникли также в некоторые языки банту и один афразийский язык — вымирающий язык дахало кушитской группы.
Но по таким случаям сложно составить цельную картину влияния контактов между носителями языков на сами языки: выявлять подобные «типологические заимствования» можно в том случае, если есть 1) исторические или географические данные о контакте между носителями языков и 2) уникальные типологические особенности, которые сложно объяснить случайным совпадением. Но эти условия соблюдаются далеко не всегда: исторические источники могут быть неинформативны или содержать противоречивые данные, а заимствуемые особенности могут быть самыми обычными и распространенными. А лингвистам хотелось бы иметь общую закономерность: насколько сильно близкий контакт предрасполагает к сближению языков? К счастью, есть хороший источник данных о контактах человеческих популяций от доисторического времени до настоящего момента — наша собственная ДНК.
Мы все отличается друг от друга небольшими вариациями в разных генах, которые называются полиморфизмами. У каждого полиморфизма — своя частота в разных популяциях. Контакт популяций неизбежно сопровождается смешанными браками, в результате чего частоты аллелей меняются и популяции становятся генетически ближе. Это позволяет использовать генетические маркеры как косвенный показатель контакта популяций и отслеживать его связь с языковыми особенностями.
В 2021 году результаты такого исследования были опубликованы в журнале Science Advances: в нем изучались языки Северо-Восточной Азии — от региональных, таких как нганасанский и бурятский, до таких известных, как японский и корейский (H. Matsumae et al., 2021. Exploring correlations in genetic and cultural variation across language families in northeast Asia). В этом исследовании были использованы три типа данных:
1) генотипы (состав однонуклеотидных полиморфизмов) — образцы частично собраны самостоятельно, частично взяты из общедоступных наборов данных других исследований;
2) данные по базисной лексике, фонологии и грамматике из общедоступных баз данных;
3) количественные и классификационные характеристики музыки рассматриваемых народов из предыдущих исследований авторов.
Эти данные сначала были подвергнуты анализу главных компонент. Затем ученые провели с этими компонентами анализ избыточности.
Подробнее о смысле и методике анализа избыточности можно узнать из презентации биолога СПбГУ Марины Варфоломеевой. Этот тип статистического анализа требует компьютерной техники. В презентации его методика показана на примере языка программирования R.
Этот анализ выявил довольно сильную связь между генетическим составом популяций (определяемым по однонуклеотидным полиморфизмам) и грамматикой тех языков, на которых они говорят (рис. 2). Чем ближе друг к другу два восточноазиатских народа генетически — тем больше вероятность, что они говорят на языках с похожей грамматикой. А лексика и фонология, наоборот, значимо не сближались в этих популяциях, даже если они были генетически близки. Это, кстати, может немного удивлять: сближение фонологии в результате контактов зафиксировано в истории языков не раз. Помимо описанного выше случая с кликсами, характерным примером являются индийские языки индоевропейской группы: в них сократилось число гласных, а звук [а] стал преобладающим — как в дравидийских языках, с которыми те контактировали. Тем не менее было ясно, что на просторах Северо-Восточной Азии происходило примерно то же самое, что в балканском языковом союзе, — просто сближение языков было выражено слабее и фиксировалось только мощными статистическими методами.
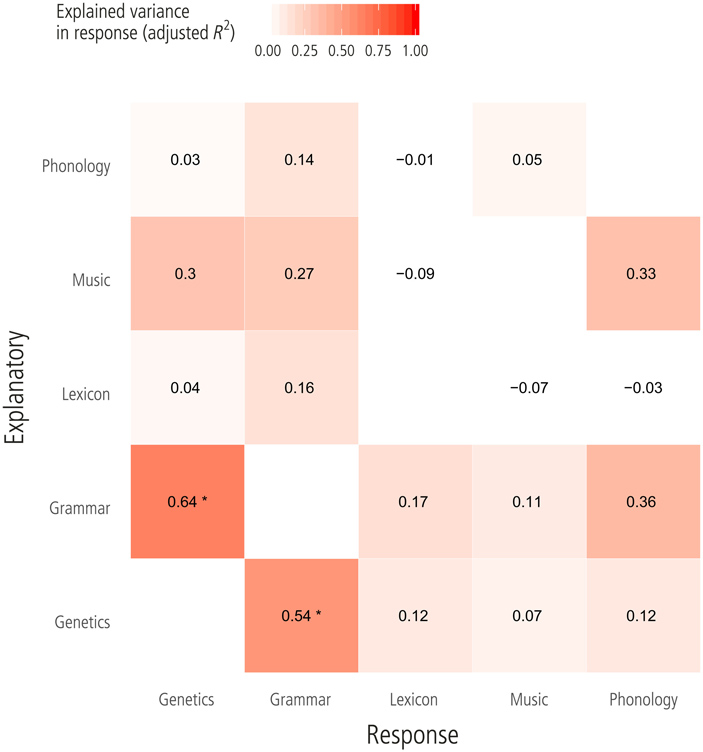
Рис. 2. Результаты анализа избыточности для связи между генетикой, музыкой и языками народов Северо-Восточной Азии, представленные в виде тепловой карты по показателю R2. Заметна средняя по силе связь между грамматикой и генетической структурой популяций. Рисунок из статьи H. Matsumae et al., 2021. Exploring correlations in genetic and cultural variation across language families in northeast Asia
Может возникнуть вопрос: а почему не сблизилась лексика, если именно лексические единицы легко заимствуются? Дело в том, что заимствования обычно составляют небольшую долю словарного фонда — особенно в языках коренных народов, в которых отсутствуют сложные научные, технические и культурные термины. Отсутствие лексической близости характерно для абсолютно не родственных языков — ведь родство устанавливается именно по звуковым соответствиям в лексике, и у родственных языков лексика была бы сближена за их счет. Здесь подобного сигнала нет, что является дополнительной проблемой для макрокомпаративистов, пытающихся выявить родство языков на уровне глубже семей. Это не первый случай, когда генетико-лингвистические исследования не находят никаких убедительных следов предполагаемых макросемей, причем снова на восточноазиатском материале (см. новости Генетических корней американских индейцев в Азии найти не удалось («Элементы», 07.07.2025) и Палеогенетики установили прародину уральских и енисейских языков («Элементы», 15.09.2025)).
Но Северо-Восточная Азия — лишь один из географических регионов, да еще и со специфическими условиями вроде холодного климата и низкой плотности населения. В холодном климате, например, невозможно нормальное земледелие, поэтому народы, исторически населяющие такие территории, обычно ведут кочевой образ жизни и занимаются животноводством. Из-за этого им сложно оставаться бок о бок с соседями продолжительное время, чтобы обмен особенностями языков был эффективен.
А прослеживаются ли похожие эффекты на всем земном шаре?
Такое исследование — значительно более сложная задача, чем упомянутое исследование 2021 года, и дело здесь не только в объеме данных. На большей части земного шара плотность населения выше, чем в Северо-Восточной Азии, а контакты были куда интенсивнее. Поэтому одномоментное исследование «в лоб» — путем сравнения нынешнего генетического состава популяций и данных по их языкам — могло ничего не дать. Авторам новой статьи в Science Advances пришлось действовать точнее и прицельнее (рис. 3) — реконструировать контакты методом анализа предковых компонент (ADMIXTURE). Генетические данные для него были взяты из общедоступной базы данных GeLaTo (GEnes and LAnguages TOgether, «Гены и языки вместе»), специально предназначенной для генетико-лингвистических исследований (см. C. Barbieri et al., 2022. A global analysis of matches and mismatches between human genetic and linguistic histories).
Важно не путать анализ предковых компонент (специализированный метод популяционной генетики) с анализом главных компонент (статистическим методом широкого профиля). Анализ предковых компонент проводится с помощью программы ADMIXTURE, принцип ее работы описан в журнале Genome Research

Рис. 3. Схема методики глобального исследования из обсуждаемой статьи. А — связи между языками представлялись в виде ориентированного графа, где популяция-источник и популяция-цель определялись по генетическому вкладу, а также учитывалась их генеалогическая классификация (популяции должны говорить на языках разных семей, чтобы исключить сходство из-за общего происхождения, — поэтому случаи, например, балканского или европейского языкового союза в глобальную выборку не попадают). На рисунке показана методика для простейшего случая, когда нынешняя популяция состоит из двух предковых компонент (K = 2). B — полный граф генетически вычисленных контактов между популяциями и языками: синие точки обозначают популяции-цели, а оранжевые — источники (которые на самом деле представляют собой совокупности популяций, говорящих на языках одной группы близкородственных идиомов, — просто здесь они центрированы по одному языку для облегчения визуализации). Всего было насчитано 126 пар «источник-цель». C — все языки, данные по которым были использованы в исследовании, — отмеченные на карте и раскрашенные по географическому региону
Но была и еще одна сложность: интенсивные контакты между популяциями земного шара происходили в разные исторические эпохи, поэтому контактировавшие языки отличались от современных. Так что вместо некоторых языков пришлось использовать реконструкции — например, вместо современных испанского и португальского при изучении их контактов с популяциями обеих Америк исследователи взяли иберо-романские диалекты XVI–XVII веков — эпохи Великих географических открытий. Нетрудно догадаться, почему.
Математически данные нового, более крупного, исследования не могут быть напрямую сопоставлены с данными предыдущей работы, выполненной на материале Северо-Восточной Азии. Если анализ избыточности в качестве силы связи дает показатель R2 — примерно как в корреляционном анализе — то в новой статье исследуется связь появления определенных сходных черт в языках с конкретными событиями контакта (правда, реконструируемыми по генетическому составу). А значит, новое исследование показывает совершенно другую величину — апостериорную вероятность наличия сходных типологических черт в языках после контакта. Проще говоря — на сколько вероятнее, что языки будут сходными по тем или иным параметрам, если говорившие на них популяции контактировали в прошлом или настоящем?
Исследователи использовали два набора данных по структурным особенностям языков, собранных из разных общедоступных баз и представленных ими же в предыдущей статье (A. Graff et al., 2025. Curating global datasets of structural linguistic features for independence). Эти два набора дают разные оценки. По одному из них вероятность сближения языков в случае генетического контакта популяций повышается на 3,9%, а по второму — на целых 7,2%. Для влияния географической близости получились более согласованные оценки: 3,4–3,5%.
В отличие от предыдущей («восточноазиатской») статьи, в обсуждаемом «глобальном» исследовании изучается не только больше языков, но и больше отдельных языковых особенностей. Отдельно исследуются:
- семантика (например, выражаются ли значения для плеча/предплечья и кисти одним словом, как русское «рука», или двумя, как английские hand и arm);
- синтаксис (например, ставится ли прилагательное перед существительным или после, глагол перед дополнением или после);
- лексические классы (например, грамматический род, классы спряжения глаголов и т. п.);
- грамматические категории (присутствие или отсутствие в языке таких грамматических категорий, как время глагола, эвиденциальность и т. п.);
- другие формальные грамматические различия (например, выражение дополнительных значений придаточными предложениями, как в русском, или структурами, напоминающими деепричастный оборот, как в казахском и турецком);
- фонология (все признаки, описывающие фонемы языка);
- просодия (ритм речи, ударение и интонация);
- вокализм (особенности системы гласных, например присутствие или отсутствие носовых гласных, которые можно услышать в польском и французском);
- консонантизм (особенности системы согласных, например присутствие придыхательных, которые можно услышать в языках индийской группы и в грузинском).
Как оказалось, некоторые из этих черт «заимствуются» лучше других. Генетический контакт популяций на 3% повышает вероятность наличия сходных синтаксических особенностей в их языках, но географическая близость не оказывает даже такого влияния. Семантические особенности лексики заимствуются еще лучше, если языки географически удалены друг от друга. Это отчасти согласуется с тем фактом, что новая лексика продолжает активно усваиваться во взрослом возрасте: именно взрослые, по общепринятым представлениям, являются «двигателями» заимствования в популяции.
Похожую тенденцию демонстрируют фонологические особенности — что тоже довольно очевидно и упоминалось выше при обсуждении языков Африки и Индии. Это немного компенсирует данные предыдущего «восточноазиатского» исследования, где связи генетики и фонологии.
Фонетика описывает полный состав звуков, которые мы физически произносим, и в любом языке он очень пестрый. Фонология описывает только те различия между звуками, которые значимы для понимания слова в данном языке. Например, придыхательность согласного или назализация гласного никак не повлияют на значение в русском языке, но совершенно изменят значение в непальском или французском соответственно. Зато в немецком и английском не важна твердость/мягкость (палатализация) согласных, а в русском она меняет значение полностью, как в словах мел и мель. Поэтому фонем в любом языке всегда меньше, чем звуков, — но именно их состав важен для понимания особенностей и эволюции языка.
Также неплохую заимствуемость (порядка нескольких процентов апостериорной вероятности, как и в случаях выше) показали лексические классы и грамматические категории, и это оказалось несколько неожиданно. Обычно такие вещи, как род существительных или спряжение глагола, усваиваются в детстве, в критический период освоения языка, и после этого способность к их усвоению падает. Так что обсуждаемое исследование показало, что мы чего-то не знаем о том, как язык функционирует «здесь и сейчас», в нашем обществе: то ли маленькие дети активнее участвуют в заимствовании слов, то ли мы недооцениваем способности взрослых. Этот пример показывает, насколько изучение эволюции языка связано с психолингвистикой и социолингвистикой.
Процентный вклад генетического контакта в сближение языков, вычисленный в глобальном масштабе, может показаться очень скромным на первый взгляд. Однако в сочетании с другими исследованиями, сосредоточенными на отдельных ареалах и случаях, он позволяет составить полную картину влияния контакта популяций на их языки. Такие исследования показывают, что известные языковые союзы — лишь верхушки айсберга. Все языки Земли (за исключением изолированных языков, на которых общаются неконтактные народы) оказываются в какой-то степени участниками сети из многочисленных «языковых союзов», — правда, обычно они проявляют себя в очень слабой степени.
Источник: Anna Graff, Damián E. Blasi, Erik J. Ringen, Vladimir Bajić, Daphné Bavelier, Kentaro K. Shimizu, Brigitte Pakendorf, Chiara Barbieri, Balthasar Bickel. Patterns of genetic admixture reveal similar rates of borrowing across diverse scenarios of language contact // Science Advances. 2025. DOI: 10.1126/sciadv.adv7521.
Георгий Куракин
-
Интересно было бы увидеть примеры подобных грамматических заимствований из английского, немецкого и французского в русский. Языки не сильно родственные, но контактов очень много. И заимствования слов очень много.
-
Заимствования появились только в последние сто-двести лет. Это только индустриальная лексика. У нас нет контактов на бытовом уровне, а тут важны именно контакты на самом примитивном бытовом-семейном уровне - родственные связи.
Ну а то что написано то банально, тут важно понимать что язык как бы постоянно делится на диалекты, распадается, каждый диалект стремится стать самостоятельным языком. Это центробежные тенденции, но в противовес им всегда есть центростремительные силы, распавшиеся диалекты всегда объединяются в единый язык. Так пока есть политическое единство или территориальное единство, если территориально язык распадается на изолированные территории, то центростремительные силы его объединяющие исчезают.


Почему именно гены? Просто рядом лежали?
Не вижу практической ситуации: папа и мама знают разные языки. Ребёнок как практиццки должен эти языки перетрансформировать? В один общий? Падежи от одного, предлоги от другого?
Как-то странно это.
Почему не поискать корреляций с ростом, полом, цветом глаз?
Вспоминаю мужичка, который искал связей в окружающем мире со своим графиком продаж. Сейфами торговал. Всех сортов, назначений и степеней защиты - от оружейных железных ящиков и огнестойких жестянок с электронными тьфу-замочками до полутонных взломостойких монстров. Оптом и в розницу.
Так вот он был очень удивлён, но постоянно убеждался, что лучше всего коррелировал с графиком его продаж - что вы думаете? - график атмосферного давления в г. Москва. Ноздря в ноздрю шли!
Несмотря на то, что он иногда делал рекламные акции и прочие неизвестные московской атмосфере, эээ... взбрыкивания. Уйти от корреляции ему не удавалось.
Думаю, надо так же, как этот мужичок: выстроить карту межъязыковых связей, и накладывать на неё все карты мира подряд. Не только генетическую.
Запросто может оказаться, что самая точная корреляция окажется с картой, например, глубин и толщина пластов грунтовых вод.
Или среднегодовых концентраций пыльцы одуванчиков. Или поясов какого-нибудь Койпера, помноженных на гравитационные аномалии.
Одна лишь генетика - это один листик многтомной энциклопедии.
Уверен, что рисунок на листике номер 3456 может показать существенно лучшее соответствие географической карте родства языков.
Мы в самом начале пути. ИИ в помощь! Пусть молотит тонны инфы.
-
Не вижу практической ситуации: папа и мама знают разные языки. Ребёнок как практиццки должен эти языки перетрансформировать?
Вставлять кальки из материнского языка. Вроде "у меня есть дом" вместо "я имею дом" или странно произносить звуки, как например у чукчей женщины меняют звуки в словах, что скорее всего пришло из другого близкого языка, родственного корякскому, потому что там замены не везде и не случайны. Именно так это и выглядит -
Много слов, содержания нет, одна бессмыслица от незнания азов. Ребенок всегда говорит не на языке мамы-папы, а на языке того общества где он живет! Он учит общий язык других детей и их родителей, потому что ему надо будет всю жизнь разговаривать с каждым человеком этого общества. Язык родителей это всегда язык мужчин составляющих это общество, у матери родной язык может быть другой, но она всегда учит язык своего мужа, потому что она должна разговаривать с мужем и его мужским обществом с их женами. В популяции всегда более половины матерей генетически родственны мужьям (женщины и мужчины составляют один народ) - это научное определение самого понятия популяции, если менее половины, то популяции не существует, это общество не составляет популяции. То есть в популяции большинство женщин разговаривает на языке своих мужей с рождения, а значит что бы общаться с женщинами (обществом женщин) пришлая женщина обязана учить язык популяции.
Поэтому именно генетика определяет все и без альтернатив, и не надо фантазировать, никакие другие факторы не определяют, только генетика популяции. Государства несколько подпортило эту картину создав иерархию популяций, когда один человек входит в несколько популяций и становится билингвом (есть язык более крупной популяции и более мелкой), но в догосударственном обществе ничего подобного небыло.-
но в догосударственном обществе ничего подобного небыло.
Было и есть. В обществах охотников-собирателей (там где их не выбили и из достаточно много) билингвизм по отцу и матери обычен. Как и вообще знание более чем одного языка. Это сейчас носитель чужого языка редок и маловажен (интернет правда опять всё сводит к распространенности других языков, пусть и виртуальной). Раньше носителей других языков было много - в соседнем племени другой могла быть языковая семья
-
Предлагаю сравнить генотипы, например, румын и болгар (входящих в языковой союз) с одной стороны и румын и их соседей украинцев (не входящих в языковой союз) с другой стороны. И если, например, румыны по генетике ближе к болгарам, македонцам и албанцам, чем к украинцам и венграм, то это о чём-то говорит. Но такие случаи должны быть проверены для многих и разных языковых союзов мира, тогда можно будет выявить корелляцию.
В принципе это логично и давно засвидетельствовано, что у контактирующих народов и языки будут иметь больше общего, чем у неконтактирующих. Но хотелось бы это как-то измерить. У авторов данной статьи это, по-видимому, не совсем получилось.
Тюрки-болгары где-то в пути на Балканы стали славянами, и но пришли на греческую почву. Пока греко-латино-фракийское население адаптировалось к языку пришельцев, пришельцы сами нахватались морфологических структур у аборигенов.
Писали, что идиш, неся словарный запас из немецкого языка, по морфологии, скорее польский или даже русский :-))
Последние новости















Рис. 1. Эта табличка в Болгарии хорошо демонстрирует отличительные особенности болгарского языка: отсутствие падежей и обилие предлогов (как в английском) в сочетании с присутствием постпозитивных артиклей. В свою очередь, эти особенности стали следствием взаимопроникновения балканских языков за счет их длительного контакта. Похожие процессы, как выяснили исследователи, происходят со всеми языками земного шара при условии, что они «контактируют» с другими языками. Фото с сайта ru.wikipedia.org