Не все языковые универсалии оказались универсальными

Группа авторов, связанная с лингвистической базой данных Grambank, занялась давним вопросом языковых универсалий и решила прояснить его статистическими методами. Исследователи проверили на имеющемся у них материале 191 импликационную универсалию (универсалию типа если A, то B) из проекта Universals Archive. Большинство универсалий вроде бы получили подтверждение. Но далее исследователи провели повторный анализ с поправкой на родство (благодаря которому у языков могут сохраняться общие черты) и географическую близость языков (благодаря которой общие черты могут заимствоваться). Оказалось, что с такой поправкой проверку проходят меньше половины всех испытанных универсалий, причем доля подтверждений для универсалий разных типов очень разная — от 25% до 80%. Однако 89 подтвержденных универсалий из 191 — это всё равно значительное количество нетривиальных общих закономерностей в морфологии и синтаксисе. И это вновь приводит к вопросу о причинах и механизмах сходства между языками в основных принципах их организации.
Одним из основных вопросов лингвистической типологии — раздела лингвистики, связанного с наиболее общими закономерностями в языке — является вопрос о языковых универсалиях. Под ними понимаются закономерности, которые (в идеале) имеют место во всех языках мира — или хотя бы соблюдаются значительно чаще, чем нарушаются. Проще говоря, универсальные законы языка.
Все языковые универсалии представляют собой строго сформулированные проверяемые утверждения об особенностях языка. И по своей форме они делятся на абсолютные и импликативные. Абсолютная универсалия выражается простым предложением — например, во всех языках есть гласные и согласные. А импликативные универсалии представляют собой утверждения формата если ..., то ... и напоминают тем самым математические теоремы.
Пример импликативной универсалии: если язык имеет порядок слов «подлежащее — дополнение — сказуемое», то в нём есть послелоги. Именно так обстоит дело в японском языке: в нём такой порядок слов в предложении, и в нём используются послелоги вместо предлогов. Так, по-японски говорят 桜のために (sakura no tame ni) — в буквальном переводе сакуры для, в то время как по-русски и по-английски говорят для сакуры. Но справедливо ли это утверждение для большинства языков?
Существуют большие списки предполагаемых языковых универсалий — например, Universals Archive. Однако было непонятно, насколько они на самом деле распространены — и насколько часто нарушаются. Для ответа на этот вопрос важно статистическое исследование большой репрезентативной выборки языков со всего мира. До недавнего времени качественных исследований на эту тему не было: исследовались слишком малые выборки языков, да ещё и методами с ограниченной статистической мощностью.
Преодолеть эти ограничения решила международная команда исследователей, ранее разработавшая базу данных Grambank. Эта база данных содержит информацию по морфологическим и синтаксическим особенностям 2430 языков со всех континентов, кроме Антарктиды (рис. 1). Помимо этого, в базе содержатся данные о локализации языков на карте мира (из базы Glottolog) и оценки степени их родства (из глобального исследования языков методами компьютерной филогенетики).
Идея исследования универсалий с использованием собственной базы данных (как отмечают сами авторы в популярном синопсисе) родилась на одной из планёрок Grambank. Для этого авторы отобрали из уже упоминавшейся базы Universals Archive 191 импликационную универсалию, для которых есть соответствия в базе Grambank. Эти универсалии были разделены на 4 группы.
- Узкие синтаксические универсалии (narrow word order), связывающие два признака, касающиеся порядка слов. Примером может служить разобранная выше универсалия, связывающая порядок слов с послелогами.
- Широкие синтаксические универсалии (broad word order), связывающие признак, касающийся порядка слов, с каким-то другим признаком, который непосредственно с порядком слов не связан. Например, в языках с эргативным строем (см. врезку ниже) глагол тяготеет к началу или к концу предложения, избегая позиции между подлежащим и дополнением.
- Иерархические универсалии связывают более редкий признак с более частым в той же категории. Например, если в языке есть двойственное число, то есть и множественное.
- Другие универсалии, не попавшие в перечисленные группы.
Эргативный строй означает отсутствие в языке винительного падежа в привычном для нас смысле слова — для выделения объекта действия. Вместо этого в предложении с переходным глаголом особым падежом выделяется активный деятель. А объект действия при этом стоит в нейтральном падеже — в том же самом, в котором стоит подлежащее при непереходных глаголах.
Такие конструкции распространены, например, в баскском языке:
- Ehiztariak otsoa harrapatzen du. — Охотник ловит волка.
- Otsoa korrika doa. — Волк бежит.
- Ehiztaria kkorrika doa. — Охотник бежит.
В русском языке волк стоит в разных падежах — именительном, если он бежит, и винительном, если его ловят. Когда волк является объектом ловли, мы маркируем его отдельным падежом (винительным, или аккузативом). А вот в баскском и бегущий волк, и волк как объект ловли стоят в одном и том же нейтральном падеже с окончанием -а, который иногда называют именительным, но чаще абсолютивом. А отдельным косвенным падежом (который называется эргативом) выделяется охотник, когда он является активным деятелем — например, ловит волка. Для индоевропейских языков эта логика необычна, но в мире в целом она распространена. Далеко ходить не надо: таких языков много на Кавказе — например, чеченский язык устроен так же, а в грузинском такие конструкции используются в прошедшем времени. Пример из грузинского языка — тоже с участием волка — разбирается в лингвистической задаче «Lupus homini amicus est».
Строй, обратный эргативному, называется аккузативным. Таковы все индоевропейские языки, включая русский, а также, например, тюркские и уральские.
Для проверки универсалий была использована байесовская смешанная обобщённая линейная модель — разновидность обобщённой линейной модели (обобщения линейной регрессии на случаи, где распределение данных отличается от нормального). Таким образом, у исследователей была и репрезентативная выборка за счёт базы Grambank, и мощный статистический метод.
Применение метода без поправок на генетическую и географическую близость привело к тому, что подавляющее большинство предполагаемых универсалий — 91% — были подтверждены (рис. 2). Подтверждение универсалии не означает, что она выполнялась для всех языков (из наличия в языке признака A всегда следовало наличие B), но во всяком случае связь между A и B оказывалась статистически значимой — то есть вероятность того, что она возникла случайно, была совсем небольшой.
Однако, такой наивный подход — не совсем правильный. Как мы уже писали в одной из предыдущих заметок, контакты между языками приводят к их статистически значимому сближению — в типологическом плане они становятся более сходными. Примером могут служить языки Кавказа: они относятся к разным семьям, но зачастую имеют общие черты вроде большого количества согласных фонем и того самого эргативного строя из врезки выше.

Рис. 2. Количество подтверждённых универсалий (синяя заливка — подтверждённые, серая — неподтверждённые). На каждой диаграмме верхняя строка — без корректировки, нижняя — с корректировкой на географическую близость и генетическое родство языков. Обратите внимание, насколько сильно падает процент подтверждённых универсалий при введении корректировки. a — все универсалии, b — иерархические универсалии, с — широкие синтаксические универсалии, d — узкие синтаксические универсалии, e — другие универсалии. Рисунок из обсуждаемой статьи
К сходному смещению приводит и генетическое родство языков: родственные языки ожидаемо типологически близки друг к другу. Индоевропейские языки аккузативные и обычно флективные; уральские — агглютинативные; во многих (но не всех!) афразийских языках корень состоит из одних согласных, а форма слов образуется гласными, встраивающимися между ними. Такое наследование типологии от общего праязыка языками-потомками может существенно повлиять на наши выводы о «языке вообще» — а ведь именно их мы хотим сделать, изучая языковые универсалии.
Поэтому в типологических исследованиях рационально вводить поправку на родство и генетическую близость языков, чтобы исключить их влияние на общую статистику. Что-то типа такой поправки ввели и авторы уже упоминавшейся статьи о языковых контактах: они просто не рассматривали пары языков из одной семьи.
Авторы из проекта Grambank тоже скорректировали расчёт с учётом генетической и географической близости языков, внеся эти два фактора в модель как две дополнительные переменные. И результаты резко изменились. Более строгий анализ подтвердил менее половины универсалий во всей выборке. Самыми живучими оказались иерархические универсалии: из 30 в этом классе устояли 24. Также была подтверждена заметная часть узких синтаксических универсалий — 36 из 65. А вот широкие синтаксические и другие универсалии оказались... в большинстве своём не универсальными.
Исследование в очередной раз подтвердило, что языки мира гораздо разнообразнее, чем казалось ранее — даже в своих основных принципах. И что далеко не всё то универсалия, что ею кажется на первый взгляд.
Какие конкретно универсалии оказались наиболее сильными? Статистическую оценку (коэффициент Байеса) для каждой из подтверждённых универсалий (и некоторых неподтверждённых) можно увидеть на рис. 3. Как и на рис. 2, голубым цветом обозначены подтверждённые универсалии.
Коэффициент Байеса — это количественное выражение поддержки одной гипотезы (в данном случае — о наличии связи между двумя признаками) по сравнению с другой гипотезой (об отсутствии связи) в байесовской статистике. С точки зрения размерности это отношение правдоподобия, поэтому он может быть и меньше единицы, и больше тысячи. Но обычно значительной поддержка считается при значении коэффициента Байеса от 10 и выше.
На рис. 2 выше используется не коэффициент Байеса, а другой показатель — статистическая оценка с фиксированными эффектами — поэтому в легенде к нему упоминается порог 0 (а не 10, как в случае коэффициента Байеса).
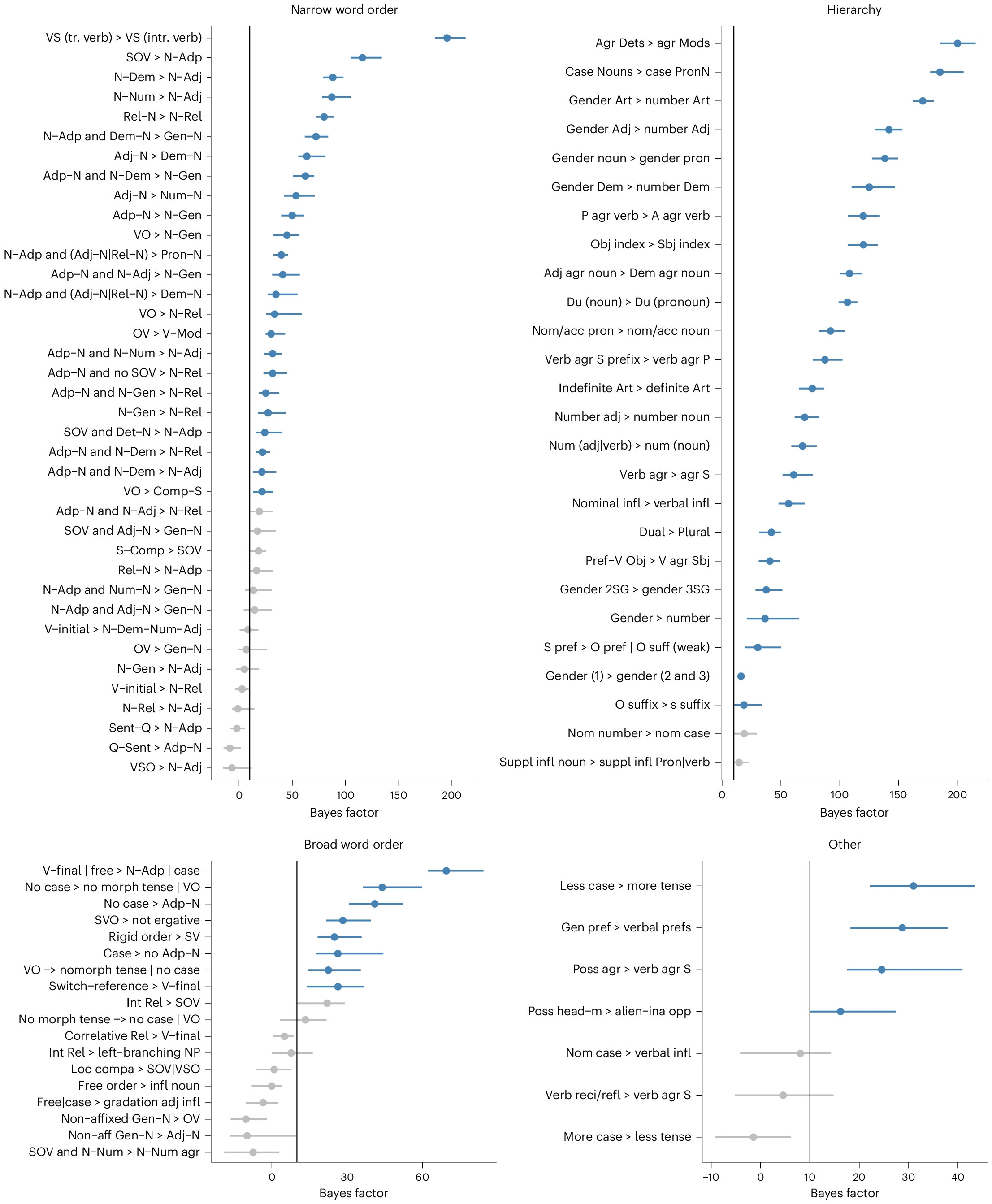
Рис. 3. Доверительные интервалы коэффициента Байеса (КБ) для каждой подтверждённой универсалии и некоторых отвергнутых универсалий. Универсалии с КБ > 10 считались подтверждёнными и обозначены синим цветом (как на рис. 2 выше). Каждая универсалия представлена сокращённым обозначением — их полный список можно найти в дополнительных материалах к обсуждаемой статье, для некоторых избранных универсалий они даны в тексте. Рисунок из обсуждаемой статьи
В числе явных лидеров среди узких синтаксических универсалий, коэффициент Байеса у которых явно далёк от пороговой «десятки», — упоминавшаяся выше универсалия в языках с порядком слов SOV используются послелоги; на рис. 3 она обозначена SOV > Ν-Adp.
По статистической поддержке её опережает другая универсалия: если сказуемое, выраженное переходным глаголом, ставится перед подлежащим, то сказуемое, выраженное непереходным глаголом, также будет предшествовать подлежащему, VS (tr. verb) > VS (intr. verb.). Также в числе лидеров в «узком синтаксическом» классе — универсалия если в языке числительное ставится после существительного, то прилагательное также следует за существительным, N-Num > N-Adj.
Несмотря на низкую поддержку класса в целом, в классе широких синтаксических универсалий есть несколько закономерностей с высокой статистической поддержкой. Например, если в языке глагол ставится в конце предложения или порядок слов свободный, то в этом языке есть послелоги или падежные аффиксы, V-final | free > N-Adp | case. В принципе, эта универсалия с некоторой натяжкой верна и для русского — если его порядок слов почти свободным считать. Но всё-таки японский или грузинский иллюстрируют её лучше.
Ещё одна лидирующая широкая синтаксическая универсалия — SVO > not ergative — выполняется, например, для русского языка. Она гласит, что языки с порядком слов «подлежащее — сказуемое — дополнение» (SVO) не эргативные. Эта универсалия эквивалентна упоминавшейся выше, согласно которой языки с эргативным строем имеют порядок слов со сказуемым в начале (VSO) или конце предложения (SOV), но не между подлежащим и сказуемым (SVO).
Возможная связь порядка слов в предложении и эргативного строя обсуждается в лингвистической задаче «Как по-какчикельски?». В ней также рассматриваются нейрокогнитивные корреляты порядка слов в предложении, полученные в исследовании методом фМРТ. Однако это исследование прямо не подтверждает и не опровергает связь эргативности с обработкой того или иного порядка слов в мозге, оставляя этот вопрос открытым.
А вот интересная универсалия, связывающая приставки и суффиксы, не подтвердилась. Предполагалось, что если в языке используются только суффиксы и нет приставок, то в нём не будет и предлогов — только послелоги. И наоборот — если в языке есть только приставки и нет суффиксов, то послелогов в нём быть не должно. Эта идея (как и многие другие из анализируемых в обсуждаемой статье) была выдвинута известным американским лингвистом Джозефом Гринбергом (Joseph Greenberg), но статистический анализ её надежно не подтвердил — коэффициент Байеса близок к десяти для обеих формулировок универсалии. В переводе на простой язык это означает, что между предпочтениями языка в плане предлогов/послелогов и в плане морфемики нет подтверждённой связи. Видимо, развиваются они либо по-разному, либо в разные эпохи.
Подтверждённые исследованием иерархические универсалии включают в себя такие признаки, как наличие склонения местоимений по падежам при наличии склонения существительных, Case Nouns > Case PronN; согласование прилагательных с существительными по числу при наличии согласования по роду, gender Adj > number Adj. Эти универсалии наверняка покажутся читателям интуитивно понятными: ведь в русском языке всё так и устроено. Наконец, подтверждение получила ещё одна универсалия, упомянутая во введении: наличие в языке множественного числа при наличии двойственного, Dual > Plural.
Из числа подтверждённых универсалий в группе «Другие» лидирует любопытная закономерность, которая покажется смутно знакомой всем англоговорящим: чем меньше в языке падежей у существительных, тем больше в нём глагольных времён, Less case > more tense. Английский язык является, можно сказать, предельным случаем этой закономерности: у существительных нет падежей вообще, но система времён очень развитая и сложная. Любопытно, что в обратную сторону эта закономерность не работает: универсалия More case > less tense статистической поддержки не получила. Видимо, языки тяготеют к развитию сложной временной системы глагола, если теряют падежи (или если их нет изначально). Но вот наличие большого количества времён не обязывает язык терять падежи. Например, в латыни система времён очень напоминала английскую, за исключением разве что отсутствия длительных (континуальных) времён. Но это не помешало латинскому языку сохранить свои шесть падежей.
Так как авторы сделали поправки на близость между языками, можно с уверенностью утверждать, что подтверждённые закономерности действуют во многих языках мира при их независимом развитии и не могут быть объяснены контактами или общим прошлым. Значит, существуют какие-то внутренние механизмы, которые обеспечивают зависимость одних структур и подсистем языка от других. Какие именно механизмы — пока до конца не ясно. Версий так много, что в основную статью они не поместились, и их пришлось выносить в приложения, что в практике научных публикаций встречается не так часто: обычно в приложениях оказываются данные и расчёты, но не обсуждение. Это показывает масштаб нашего незнания тех причин, которые делают наши языки похожими друг на друга.
В общем и целом, если передавать все обсуждения в двух словах, то глубинные причины универсалий могут крыться в когнитивных процессах или в механизмах развития языка. Не случайно редакционная коллегия журнала Nature Human Behaviour, где опубликована обсуждаемая статья, написала на неё короткий публичный отзыв, где указала на «непосредственное отношение» языковых универсалий «к пониманию природы человеческого языка». Сама тематика исследования может показаться сложной или узкоспециальной — но на самом деле подобные работы позволяют глубже понять, на чём строится наша способность говорить.
Источник: A. Verkerk, O. Shcherbakova, H. J. Haynie, H. Skirgård, C. Rzymski, Q. D. Atkinson, S. J. Greenhill & R. D. Gray. Enduring constraints on grammar revealed by Bayesian spatiophylogenetic analyses // Nature Human Behaviour, 17.11.2025.
Георгий Куракин
-
А зачем это все?
Ллм как система которой наплевать на язык решит любой перевод...
Смысл дальнейший подобных исследований?-
Во-первых, LLM не безупречны, и у них есть свои недостатки, особенно на языках с необычным строем или типологией. Примеры недостатков можно найти в моей статье о тестировании LLM для перевода на праиндоевропейский.
https://habr.com/ru/articles/967784/
И это только верхушка айсберга. Я переводчик научных и медицинских текстов, член Союза переводчиков России, использовать ИИ обожаю, но не доверяю даже DeepL'у - всё перепроверяю за ним и постредактирую по сто раз. Без лингвистических исследований и знаний я бы не знал, на что обращать внимание.
Потом, сами-то LLM в капусте находят? Или их аисты приносят? Чтобы их разрабатывать, требуется огромный массив лингвистических исследований - даже больший, чем требовалось раньше.
Извините, но Ваш вопрос сродни фонвизинскому: "Зачем вообще нужна география? У меня есть кучер, он меня куда надо довезёт".-
Как не парадоксально, но тут фонвизинское правда.
Через пару лет по мере расширения обучающей выборки ллм превзойдут в математике, переводе и ? почти любого человека.
Все эти правила превратиться в "парафизику", "нетрадиционную медицину" и прочее... Мир изменился и это надо как бы было неприятно признать.-
Через пару лет по мере расширения обучающей выборки ллм превзойдут в математике, переводе и ? почти любого человека.
неверно. Во-первых, выявление универсалий весьма и весьма связано с выявлением формирования человеческой разумности, а это просто интересно. Во-вторых, при достижении высокого качества перевода LLM будет получен тот же результат, формирование блока универсалий, через который и будет получаться перевод.
"Насыпаем все данные подряд и получаем могучий ИИ" - дилетантская ошибка.
-
-
-


Это ж вроде как математики при расчетах друг дружке кивали бы с умным видом: "да, шестью восемь сорок восемь, я согласен, да так и все говорят" - и никто ни разу не пересчитал!
Ну, повезло нам, дожили мы до прекрасных времен, когда такие проверки делать стало легко, сама конструкция ИсИна способствует анализу больших куч хлама и поиску закономерностей - то бишь "универсалий".
Теперь пойдем семимильными шажищами!
-
Это ж вроде как математики при расчетах друг дружке кивали бы с умным видом: "да, шестью восемь сорок восемь, я согласен, да так и все говорят" - и никто ни разу не пересчитал!
Не только говорят, но хором поют!
https://www.youtube.com/watch?v=tlglAPc9CVc&list=RDtlglAPc9CVc
У кого друзья ни спросим
Шестью восемь сорок восемь -
Вот все мы верим, что мир состоит из атомов, а кто конкретно проверял, что, к примеру, Эйфелева башня тоже из них состоит? Может какой-то ее кусок сделан из неизвестных науке частиц?
Универсальные особенности формирования и развития языков хомо могут быть связаны с функциями неокортекса, ответственного за символическое мышление (?).
Почему не существует такого же (подобного) универсализма в ПОНИМАНИИ разных языков, если развивались они по одним законам? Обработка и анализ речевых сигналов должна производится в том же неокортексе... Или я сильно механически и примитивно это понимаю?
-
Язык как раз и служит инструментом универсализма в общении между людьми (и другими животными). А разные языки - разные универсализмы. И не только язык, но и "система понятий". Два разных человека могут смотреть на одну и ту же картину, книгу, фильм и видеть в них совершенно разный смысл. Язык же даёт людям, говорящим на нем, универсальную базу, стандарт для описания вещей, событий, действий и т.д. А два разных языка - две разные базы, и никакого универсализма в понимании между ними быть не может. Только человек (или ИИ), знающий оба языка - банальная истина - может перевести с одного на другой.
-
Да! Шикарная мысль! Прям в трепет... Неужели мы уже на пороге такой возможности?! Поверить алгеброй гармонию! Тут рукой подать до фольклора.
Ну, как численные коэффициенты меж "во саду ли, в огороде" и "где же ты моя Сулико". Лишь пока только с языками, без песен.
Только вот не соображу:
Взять, как Евклид, 7 самых... прекрасных(?) универсалий - и на основе их срабатывания расставить языки по ранжиру!
В ту сторону я мыслю?
Эргативный строй означает отсутствие в языке винительного падежа в привычном для нас смысле слова — для выделения объекта действия. Вместо этого в предложении с переходным глаголом особым падежом выделяется активный деятель. А объект действия при этом стоит в нейтральном падеже — в том же самом, в котором стоит подлежащее при непереходных глаголах.Ну все понятно в SVO чтобы стать объектом действия нужно перейти в новый падеж, а в эргативной языке, чтобы стать субъектом действия нужно перейти в новый падеж.
То-есть по-дефолту носители эргативного языка объекты действия, а SVO - субъекты.
Значит, существуют какие-то внутренние механизмы, которые обеспечивают зависимость одних структур и подсистем языка от других. Какие именно механизмы — пока до конца не ясно.Разная «грамматическая перспектива» на мир: Носитель SVO считается себя «по умолчанию» активным участником действия, а носитель эргативного языка — пассивным. Неудивительно, что большая часть мира принадлежит SVO.
Этнолингвисты отмечают, что эргативные языки чаще встречаются там, где:
Географическая изоляция (горы, острова, пустыни)
Малое население и малые сообщества
Сложная флексия / агглютинативная морфология
Отсутствие интенсивного языкового контакта с «внешними» аналитическими языками
-
Всё это, конечно, замечательно. Только SVO — не самый распространённый порядок слов. SOV встречается несколько чаще. То, что за счёт экспансии распространение получили SVO-языки (представители и.-е. языковой семьи, а ещё точнее, германо-романские), наверно немного другой вопрос. Я бы не стал увязывать между собой удельный вес активистов, способности к экспансии и порядок слов таким прямолинейным образом.
-
наверно немного другой вопрос. Я бы не стал увязывать
Если ваша аргументация сходу перешла на уровень фантазий, считаю необходимым ответить в том же стиле: а я бы стал увязывать! Есть возражения?
Лучше подумайте, почему часто эргатив ограничен только прошедшим совершённым временем, как в грузинском и почему эргатив возникает из пассивно-перфектных конструкций. -
Вы это что же это тут, на пути дерзающей мысли препоны ставить? Куда как? Почем опиум? Мракодел!
Уважаемый Кбоб нашел универсальный ключик к возникновению цивилизации:
Пока людей мало, они склонны говорить о себе в третьем лице, в винительном падеже, когда собрались в кучу - почуяли силу, освоили громкое "Я" и именительный падеж! И тогда-то вот карта и поперла!
Так что мировоззрения барокко и рококо рулят!
Отсюда недалеко и до понимания, почему инопланетных цивилизаций не наблюдаем никак покамест.
Зато уж понятно, что когда с ними стакнемся - первым делом язык нужно новый творить, новую степень самостоятельности, возможностей и ответственности в самоназвании зафиксировать!
И лишь потом - вперед, к новым рубежами!
))-
В русском языке по умолчанию говорящий мыслит через деятеля. Русская грамматика закрепляет агентную, деятельную картину мира.
В эргативном языке говорящий по умолчанию мыслит через результат действия. Грамматика закрепляет событийную картину мира: важнее «что произошло», чем «кто это сделал».
Русская (SVO) логика:
Я сломал палку.
центр: Я = деятель + ответственный
Эргативная логика:
Палка сломал Я-ЭРГ (нет эквивалента в русском языке), насяльника!
центр: палка = то, с чем произошло событие
человек = источник действия, но не «главный участник»
Эргативные языки часто возникают и сохраняются: в малых, изолированных сообществах, где жизнь воспринимается как заданная природой, традицией, судьбой, где меньше индивидуалистической «агентной» перспективы. Грамматика не говорит: «это твоя воля сделала», а скорее: «так случилось; ты был тем, через кого это случилось».
Номинативный язык:
Быть деятелем — норма.
Быть объектом — особое положение.
Эргативный язык:
Быть участником события — норма.
Быть деятелем — особое, отмеченное положение.
-
-
Настоящей универсалии не нужны никакие поправки: она либо есть, либо нет.
-
Мой вопрос - почему эти универсалии непонятны всем людям, если они действительно универсальны? Мой ответ - потому-что их не существует. Мозг работает по-другому...
-
Существуют. Во всех языках есть гласные и согласные (то есть нет ни одного языка, где есть только гласные или только согласные). Во всех языках есть местоимения (слова типа "я", "он", "ты").
Но что вы хотите этим понять? Конечно, этого недостаточно, чтобы понимать другие языки, а вы что хотели? Одинаковые слова во всех языках — такого нет. Но структура языков имеет одинаковые элементы. -
Во всех языках есть местоимения (слова типа "я", "он", "ты").
Это есть не в языках - это есть в сознании. Без таких понятий общение вообще не возможно.
-
Современные ученые пытаются найти в разных языках некие универсальности, то, что их (языки) может связывать/объединять эволюционно и исторически.
Как мне кажется получается плохо, потому что носители разных языков друг друга не понимают…
-
Получается хорошо. Компьютеры тоже друг друга не поймут, если кодировки разные, хотя универсалии у них могут быть одинаковы: размер машинного слова, даже команды процессора совместимы. Мозги у нас одинаковые и создают одинаковые средства: дети в состоянии усвоить язык родителей, хотя мозгов у них в этот момент немного. Вот ифкуили всякие похоже без универсалий, но на них и сам автор обычно говорить не в состоянии
-
Можно ли понимать так, что в человеческих мозгах изначально (врожденно) существуют некие "универсалии", а чуть позже возникают "кодировки" (по аналогии с компьютерными), позволяющие усваивать "язык родителей"? Что-то здесь не то...
-
Можно ли понимать так, что в человеческих мозгах изначально (врожденно) существуют некие "универсалии",
Именно так и есть. По-моему это должно быть очевидно. Иначе бы у нас половина детей или больше были бы маугли.-
они были бы ВСЕ маугли, если бы воспитывались в среде животных, а не человеческом социуме. Ни языковых ни прочих человеческих "универсалий" у новорожденных нет!...
-
Ни языковых ни прочих человеческих "универсалий" у новорожденных нет!…
За младенцев обидно. Зря Вы так. У них самые универсальные "универсалии".https://ru.wikipedia.org
/wiki/Младенец
Плач у маленьких детей является первым вербальным способом общения,
Наряду с врождёнными рефлексами у новорождённых есть и врождённые предпочтения.
(признаком здоровья считается деградация большей части этих рефлексов)
Например, младенцы могут смотреть на одни изображения дольше, чем на другие.
Уже с рождения младенцы могут подражать мимике лица взрослых людей в зависимости от уровня развития своей моторики.
Исходя из результатов авторы эксперимента сделали вывод, что уже с рождения младенец способен распознавать по крайней мере 3 различных выражения лица[36].
Начиная с 2 месяцев младенец способен использовать звуки для коммуникации.
Также младенец уже знает базовые свойства родного языка и способен отличить его от иностранных, что было показано исследованиями, проведёнными А. Кристоф и Дж. Мортоном.-
боюсь, что автор Вашей ссылки выдает желаемое за действительное.
Плач новорожденных никак не может быть свидетельством неких языковых универсалий человека!младенец уже знает базовые свойства родного языка и способен отличить его от иностранных, что было показано исследованиями, проведёнными А. Кристоф и Дж. Мортоном
Не читал. Но верю. В каком возрасте?
Зато я уверен, что только что родившийся никаких подобных "универсалий" в голове не имеет.
Известны случаи, слава богу очень редкие, воспитания человеческих детёнышей в среде животных. Они не только говорить, они даже ходить на двух ногах не умеют! О каких врожденных "универсалиях" тут может идти речь? Человека делает человеком СОЦИУМ. Безусловно используя врожденные биологические возможности - мозг, голосовой аппарат и пр...-
Плач новорожденных никак не может быть свидетельством неких языковых универсалий человека!
Ну да. Какая же это языковая универсалия, если все новорожденные плачут одинаково:)
Поэтому назовем плач вербальным сигналомНе читал. Но верю. В каком возрасте?
2 месяца. Младенцы все схватывают на лету.Они не только говорить, они даже ходить на двух ногах не умеют! О каких врожденных "универсалиях" тут может идти речь? Человека делает человеком СОЦИУМ.
А социум порождает гипертрофированный рефлекс подражания и генетически обусловленная деградация других рефлексов. Тут как минимум есть одна настоящая универсалия, заключающаяся в отказе от врожденных универсалий. Возникают невиданные возможности для возникновения и эволюции мемом Докинза.
-
-
А социум порождает гипертрофированный рефлекс подражания и генетически обусловленная деградация других рефлексов. Тут как минимум есть одна настоящая универсалия, заключающаяся в отказе от врожденных универсалий. Возникают невиданные возможности для возникновения и эволюции мемом Докинза.
Очень оригинально. Но мне кажется, что речь шла именно о врожденных, а не приобретенных (культурных) "универсалиях" ?
К чему же приводит отказ от врожденных универсалий ? Вернёмся к языку?-
В статье речь об изобретенных разными обществами универсалиях (мемах). Врожденные погребены под их много тысячелетним слоем. Отказ от врожденных универсалий, в угоду подражанию и обезьянничеству, приводит к появлению большого количества разных культур. Дети, без должного присмотра родителей, норовят придумать свой собственный язык, или какую-нибудь другую дичь.
-
В статье речь об изобретенных разными обществами универсалиях (мемах). Врожденные погребены под их много тысячелетним слоем.
Ну хорошо , согласимся, что "врожденных" универсалий нет. Есть приобретенные - в т.ч. языковые. Что совершенно логично. По поводу чего копья тут ломали?-
Чтобы быть понятным и пОнятым, коммуникативному агенту необходимо вербально и невербально представить свое внутреннее состоянии в максимально сжатом виде, сохраняя лишь ту информацию, которая наиболее полезна для взаимопонимания или координации.
Очевидно, что врожденными универсалиями тут не обойтись, поскольку внутренний мир взрослого человека чрезвычайно богат, как эмоционально, так и интеллектуально.
Практика показывает, что отображение между внутренней семантикой (убеждениями и ожиданиями индивида) и внешними символами (языковыми сообщениями) не является универсальным и носитель одного языка не понимает носителя другого.
Однако семантическая согласованность достигается на более высоком уровне - сжатия мысли в форму, пригодную для коммуникации, реализует языковые универсалии, которые демонстрируют общность мышления носителей разных языков. Именно поэтому существует такая нетривиальная возможность как перевод с одного языка на другой!
Вопрос языковые универсалии и они не абсолютно универсальны, некоторые люди мыслят не так как все?-
Очевидно, что врожденными универсалиями тут не обойтись, поскольку внутренний мир взрослого человека чрезвычайно богат, как эмоционально, так и интеллектуально.
Вообще-то и смысл "универсалий" пропадает, если они не врожденные? Или как?Однако семантическая согласованность достигается на более высоком уровне - сжатия мысли в форму, пригодную для коммуникации, реализует языковые универсалии, которые демонстрируют общность мышления носителей разных языков
Вот это другое дело. Возможно, существуют не языковые универсалии, а универсалии мышления?-
такую статейку интересную читаю
https://arxiv.org/pdf/2512.01081
автор рассуждает о возникновении разума в контексте языка и коммуникации, однако мне кажется есть следующая иерархия:
Онтология → Эпистемология → Герменевтика.
Языковые универсалии следуют из универсалий мышления, а те, в свою очередь, из универсалий бытия.-
Языковые универсалии следуют из универсалий мышления, а те, в свою очередь, из универсалий бытия.
По-моему мы уже забыли, что такое эти универсалии и откуда мальчик вообще. Авторы статьи решили утвердить или наоборот опровергнуть существование неких изначально присущих людям вербальных свойств. То есть способностей к речи.
От универсалий речи дошли до универсалий мышления, а теперь и до универсалий бытия? Не пора ли остановиться?
-
-
-
-
-
-
-
-
-
-
-
в человеческих мозгах изначально (врожденно) существуют некие "универсалии",Изначально существуют только эгоистические универсалии - отдайте мне Гренландию, потому что я так хочу, ты виноват уж тем, что хочется мне кушать. Позже, когда человек взрослеет и становится дееспособным это вступает в противоречие с законами, поэтому язык обозначает не только предметы и действия, но и волю, ответственность и морально-этическую позицию субъектов.
Например можно сказать "окончательное решение какого-то вопроса" и это будет выглядеть нейтрально, с точки зрения ответственности.
Или: Сталин подписал смертный приговор тысячам невиновных, на грузинском эргативном (в прошедшем времени) языке звучит более нейтрально:
В приговоре смертной казни тысячам невиновных — был подписантом тов. Сталин (ЭРГ-падеж). Подписан рукой тов. Сталина - наиболее близкой по смыслу вариант!
Как писал Оруэл - пора изобретать новояз!
И строчка: Я русский бы выучил только за то, что им разговаривал Ленин, приобретает совсем другой смысл.
У нас с Лениным одинаковые универсалии!
Ну, к примеру так: язык (человеческий) нужен для передачи информации одним человеком другому. Какую информацию передают друг другу люди? Например, о неком событии, которое произошло. В событии есть тот, кто совершил действие, само действие, объект действия и т д - отсюда берутся подлежащие, сказуемые дополнения и т.д. Это видимо и должно быть универсальным, ведь события, передаваемые речью, обычно похожи. Такой-то человек сделал то-то и то-то с неким предметом, таким-то образом.
Так же, как языки программирования имеют свои универсалии - conditional jump, loop, и т.д., потому что языки программирования нужны для обработки данных на компьютере.
Ну, и языки пчел (танцы) тоже разные у разных видов пчел, но у них свои универсалии, обусловленные тем, для чего это язык нужен: чтобы одна пчела могла рассказать другим, где цветут цветы, куда к ним лететь и т.д.
Тогда универсалии языков естественно получаются из того, какую информацию эти языки передают.
Такая аналогия: можно было долго собирать информацию о местоположении и движении планет, но пока не появилась модель, объясняющая причину этого движения - закон тяготения и др. законы Ньютона - универсалии движения планет не были правильно описаны.
-
Так же, как языки программирования имеют свои универсалии - conditional jump, loop, и т.д., потому что языки программирования нужны для обработки данных на компьютере.
Нет там таких универсалий.
Императивные языки → if, goto, loop
Декларативные / логические / функциональные могут:
не иметь if как оператора,
не иметь явных циклов,
не иметь переходов управления вообще.
Примеры:
Prolog: нет if, нет loop, управление задаётся через унификацию и поиск решений.
SQL: нет циклов в классическом смысле.
Haskell: нет переходов управления; рекурсия вместо циклов, if — выражение, а не оператор.
В языках программирования не существует синтаксических универсалий, а лишь семантические.
В любом разговорном языке есть универсальная необходимость кодировать событие и участников. -
В событии есть тот, кто совершил действие, само действие, объект действия и т д - отсюда берутся подлежащие, сказуемые дополнения и т.д. Это видимо и должно быть универсальным, ведь события, передаваемые речью, обычно похожи.
Логично. Непонятно другое - почему вербализация этих очевидных универсальностей оказывается столь различной в разных группах одинаково организованных мозгов, что понимание друг друга представителей различных групп после нескольких тысячелетий изоляции становится невозможным? Универсалии не дают ответа.
Лексика связана просто с обозначением различных предметов и действий. Вряд ли универсалии тут имеют место. С грамматикой уже сложнее. Как увязать эти предметы, действия, явления в осмысленные предложения решается установлением неких связей в соответствующих мозговых структурах (неокортексе?).
Лексика связана просто с обозначением различных предметов и действий. Вряд ли универсалии тут имеют место. С грамматикой уже сложнее.На самом деле всё ровно наоборот.
-
с чего Вы взяли что наоборот? Есть такой пример - восточнославянские (русский, украинский, белорусский) грамматически очень близки. И их носители хорошо понимают друг друга. Но лексический состав украинского ближе к западноукраинским (польскому, например), и дальше от русского.
-
Если вы внимательно читали, фактор общего происхождения при изучении универсалий попытались устранить. Не совсем понятно, к чему ваш пример. Да и понимание русскими двух других вост.-славянских языков несколько преувеличено, мягко говоря. В обратную сторону это работает благодаря общему тяжёлому наследию.
-
Не совсем понятно, к чему ваш пример
Я только возразил VladNSK по поводу лексики и грамматикипонимание русскими двух других вост.-славянских языков несколько преувеличено
Возможно. Непонимание связано опять же с лексикой.
Кстати известные языковые древа (Старостина, Сводеша и др.) базируются, насколько я знаю, исключительно на лексике. А это при определении происхождения, связи, динамики развития языков, всё же неправильно.-
Да, вы безусловно правы насчёт списков. Да, в них используются универсальные концепции, но в несколько ином смысле, чем в обсуждаемой статье. Это просто слова для понятий, которые есть в любом языке. Но тут они используются исключительно для глоттохронологии, чтобы оценить расхождение языков. Ядерная лексика неохотно заменяется какими-то заимствованиями. Она меняется более предсказуемо, чем грамматика, поэтому и позволяет дать какую-то оценку времени расхождения языков ну или степень похожести в некоторый момент времени. Как один из многих, этот метод тоже используют для оценки развития языков и похоже он рабочий, хотя возможно и не идеальный. Но в этой области вообще трудно найти что-то идеальное :)
-
-
-
-
В обратную сторону это работает благодаря общему тяжёлому наследию.
что за "обратная сторона"? Заинтриговали-
-
Асимметрия во взаимопонимании. Причины её довольно прозаичныи.
Ваши загадки я не собираюсь разгадыватьони используются исключительно для глоттохронологии, чтобы оценить расхождение языков. Ядерная лексика неохотно заменяется какими-то заимствованиями. Она меняется более предсказуемо, чем грамматика, поэтому и позволяет дать какую-то оценку времени расхождения языков ну или степень похожести в некоторый момент времени.
Этим принятые методики и порочны. Многие иностранные слова (даже из базовых списков) легко внедряются в чужой лексикон , но родословную языков не отражают. Грамматика более фундаментальный признак расхождения языков.-
Позвольте с вами не согласиться. Вот вам пример: китайский и вьетнамский языки. Оба очень тяготеют к изоляции (то есть словоизменение там рудиментарное, почти отсутствует). Базовый порядок слов SVO и там, и тут, причём он определяет смысл, то есть жёсткий. В грамматике принципы одинаковые в обоих языках. Поверхностно даже слоги выглядят где-то одинаково. Тоны вероятно появились под влиянием китайского. Есть мощный пласт сино-вьетнамской лексики. Казалось бы, а что вообще отличает вьетнамский от целой пачки китайских языков? Лексика! Исконная аустроазиатская лексика и делает вьетнамский непохожим на китайские языки при очень схожей грамматике. Так что метод хоть и небезупречный, но рабочий. Аналогично, кстати, раз уж речь зашла о китайских языках, то грамматика там тоже не сказать что разительно отличается. Основные различия в фонетике и... В лексике. Вот вам с ходу пример.
-
Аналогично, кстати, раз уж речь зашла о китайских языках, то грамматика там тоже не сказать что разительно отличается. Основные различия в фонетике и... В лексике. Вот вам с ходу пример.
Полностью согласен!
Только есть и более простые примеры.
В школе и универе каждый из нас изучал английский. Ну, может быть, немецкий или французский. Это не важно.
Так вот, грамматику английского языка можно выучить и понять, ну, за месяц, если постараться.
А вот лексику английского языка нужно учить годами.
-
-
-
-










Рис. 1. 2226 проанализированных языков из базы данных Grambank на карте мира. Чем темнее цвет точки, тем на большее число универсалий проверялся язык. Рисунок из дополнительных материалов к обсуждаемой статье