Фредерик Сенгер: человек, который научил нас читать
Марина Молчанова
«Квантик» №9, 2019

«Жизнь есть текст». Эту фразу разные люди толкуют по-разному — например, что мы пишем свою жизнь как книгу. Но для биологов и химиков жизнь является текстом в самом конкретном смысле. Потому что основы жизни зашифрованы в строении определённых молекул, где одни и те же звенья — буквы наших текстов — располагаются одно за другим в том или ином порядке. Научившись определять последовательность звеньев, мы можем «читать» молекулы так же, как читаем последовательность букв в тексте. И, читая их, узнаём всё новые вещи о нашем здоровье и болезнях, о нашем происхождении, о наших внешних и внутренних чертах.
На звание «главных для жизни» претендуют два типа молекул.
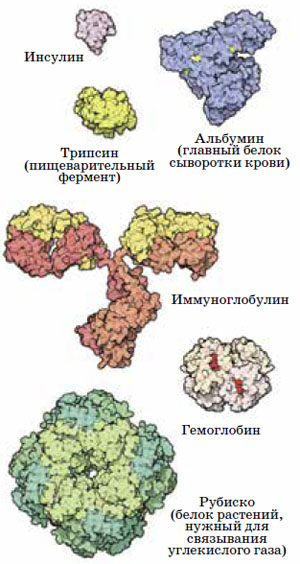
Некоторые важнейшие белки
Во-первых, это белки. Именно белки служат основным «строительным материалом» наших клеток. Но белки — это и ферменты, которые ускоряют процессы в организме, и иммуноглобулины, участвующие в работе иммунной системы, и сигнальные и транспортные молекулы, и многое, многое другое. Трудно представить себе такие события внутри и снаружи живых клеток, в которых не принимали бы участие белки.
Во-вторых, это нуклеиновые кислоты — ДНК и РНК. Хотя, может быть, всё-таки именно про ДНК надо сказать «во-первых», а про белки — уже «во-вторых». Ведь именно в ДНК записана вся наследственная информация — значит, от неё зависит, какими будут белки в каждом конкретном организме.
И белки, и ДНК — это линейные молекулы, где звенья следуют одно за другим, образуя длинную цепочку. В остальном они непохожи. И тем более удивительно, что умением «читать» и цепочки белков, и цепочки ДНК мы обязаны одному и тому же человеку. Это Фредерик Сенгер (Frederick Sanger), единственный учёный, который дважды получил Нобелевскую премию по химии: как раз за чтение белков и ДНК.
***

Колледж Св. Иоанна в Кембридже. Здесь Сенгер учился
Сенгер родился в английской деревне в 1918 году. Его семья была достаточно обеспеченной и смогла дать детям образование. И поскольку Фредерик закончил школьную программу с опережением на год, в последний год у него было время для работы в лаборатории под руководством учителя химии. Именно тогда он всерьёз задумался о научной карьере. В 1936 году Сенгер поступил в один из колледжей Кембриджского университета. С математикой и физикой у него было не очень хорошо, а вот химия, биохимия и физиология увлекли его по-настоящему.
Из-за своего религиозного воспитания Сенгер был принципиальным противником войн (кстати, именно в компании антивоенных активистов он познакомился со своей будущей женой) и в 1939 году отказался от военной службы — может быть, это спасло ему жизнь, ведь Вторая мировая война была совсем близко. Так что некоторое время он занимался социальной работой и при этом готовился к будущим научным изысканиям.
С самого начала работа Сенгера касалась белков, про которые тогда знали совсем мало. И в 1943 году он начал исследования структуры инсулина, которые позже принесли ему славу и первую Нобелевскую премию.
Затем Сенгер долго занимался изучением молекул РНК. Его группа получила немало интересных результатов, но в 1970-е годы эти результаты были заслонены более поздним его достижением: изобретением метода чтения ДНК, который за считанные годы изменил весь пейзаж молекулярной биологии и генетики. Закономерно, что и за это достижение Сенгер был удостоен Нобелевской премии — в 1980 году.

Институт Сенгера

Сенгер в старости
Впрочем, в 1983 году Сенгер отошёл от активной научной работы и в дальнейшем жил недалеко от Кембриджского университета, возделывая свой сад. Но в нескольких милях от его дома вскоре был основан институт, названный его именем и позднее принимавший активное участие в реализации проекта «Геном человека».
Сенгер умер в 2013 году, в глубокой старости. Все его коллеги говорили, что он обладал исключительной научной добросовестностью и при этом был — что сейчас нечасто встречается — равнодушен к почестям. Про себя Сенгер говорил, что он «просто парень, который возился в лаборатории» и к тому же «не отличался блестящими успехами в учёбе».
Чтение белка
Молекулы белков — цепочки, состоящие из 20 различных типов звеньев (эти звенья называются аминокислотами). Самих звеньев может быть от десятков до многих тысяч — всё зависит от конкретного белка. Конечно, начинать чтение имело смысл с самых простых белков. И Сенгер выбрал инсулин. Вы, наверное, слышали об этом веществе: это гормон, который важен для обмена глюкозы, и при его недостатке развивается тяжёлая болезнь — сахарный диабет.
В бычьем инсулине, который изучал Сенгер, две цепочки: в одной 21 аминокислота, в другой 30. Сенгер легко отделил эти цепочки одну от другой, но что делать дальше? Ведь не было способов «отщеплять» аминокислоты по одной с концов молекулы, чтобы узнать, что за чем следует. А если разрушить цепочку полностью, до единичных звеньев, то мы узнаем, какие аминокислоты в ней есть и в каком количестве, но не узнаем, где какая расположена.
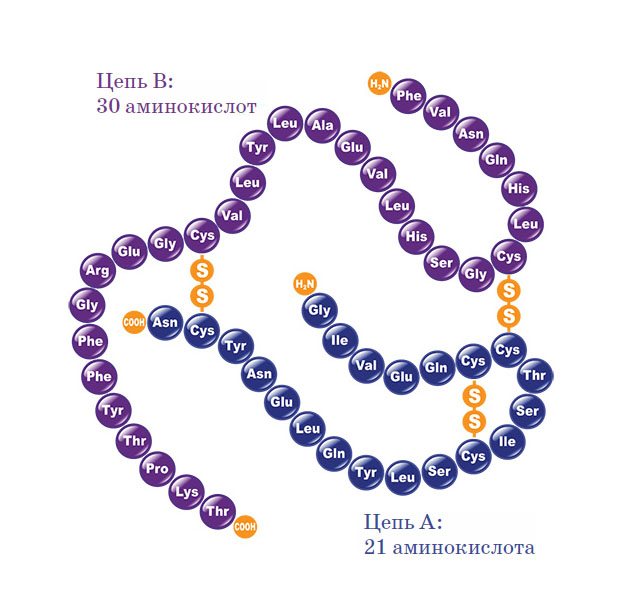
Структура инсулина. Видны две связанные цепи
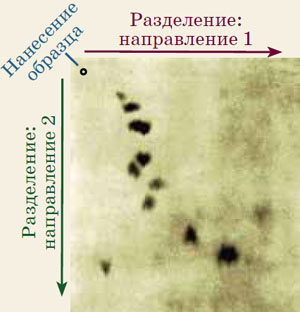
«Отпечатки пальцев»
Поэтому Сенгер действовал так. Он нашёл особый ярко-жёлтый реактив, которым можно «пометить» определённый конец любой цепочки аминокислот. Далее, он «нарезал» каждую из цепей инсулина на более короткие — то есть разрушал молекулу, но не полностью. А затем он разделял короткие фрагменты двумя разными методами в двух разных направлениях на листе фильтровальной бумаги. Разные фрагменты перемещались в разные места, создавая картину, которую Сенгер назвал «отпечатками пальцев». При этом концевой фрагмент был хорошо виден по жёлтой метке. По-разному нарезая цепочки инсулина, сверяя одни «отпечатки пальцев» с другими, каждый раз определяя аминокислоты на концах фрагментов с помощью той же самой жёлтой метки, сверяя перекрывающиеся кусочки и собирая их в более длинные, Сенгер после долгой и кропотливой работы установил последовательности аминокислот в обеих цепях.
Метод был не слишком удобным. Но основная заслуга Сенгера была не в разработке метода и даже не в том, что он узнал, как устроен инсулин. Главное — он показал, что молекула белка имеет совершенно определённый состав (раньше это не всем было очевидно!), определённую последовательность аминокислот, причём для каждого белка эта последовательность уникальна. А значит, можно и нужно определять последовательности и для других белков. Более того — вскоре учёные выяснили, что эти последовательности определяются ДНК. И это стало одной из основ современной биохимии.
Чтение ДНК
Молекулы ДНК построены совсем не так, как молекулы белков. В «алфавите» ДНК не 20, как у белков, а всего четыре буквы: А (аденин), Г (гуанин), Ц (цитозин) и Т (тимин). И всё разнообразие жизни закодировано различными последовательностями этих четырёх букв*.
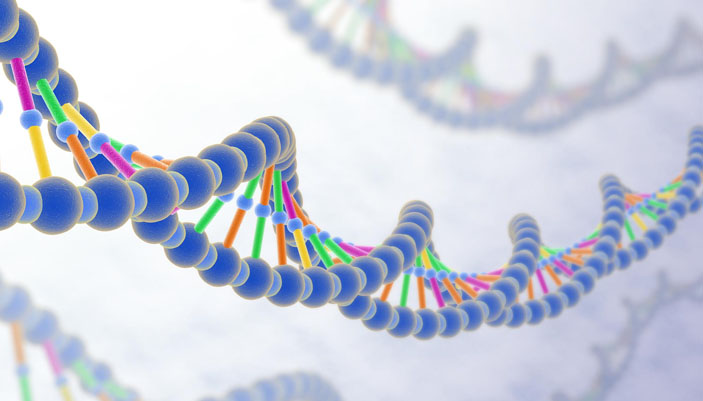
Молекула ДНК имеет структуру двойной спирали
При этом в каждую молекулу ДНК входит не одна, а две нити, но одна из них полностью определяет другую: напротив Г в одной цепочке всегда стоит Ц в другой (и наоборот), а напротив А стоит Т (и наоборот). Это нужно для того, чтобы при делении клетки можно было легко получить точную копию любой молекулы ДНК: она разделяется на две нити, и на каждой однозначным образом достраивается вторая (рис. 1).
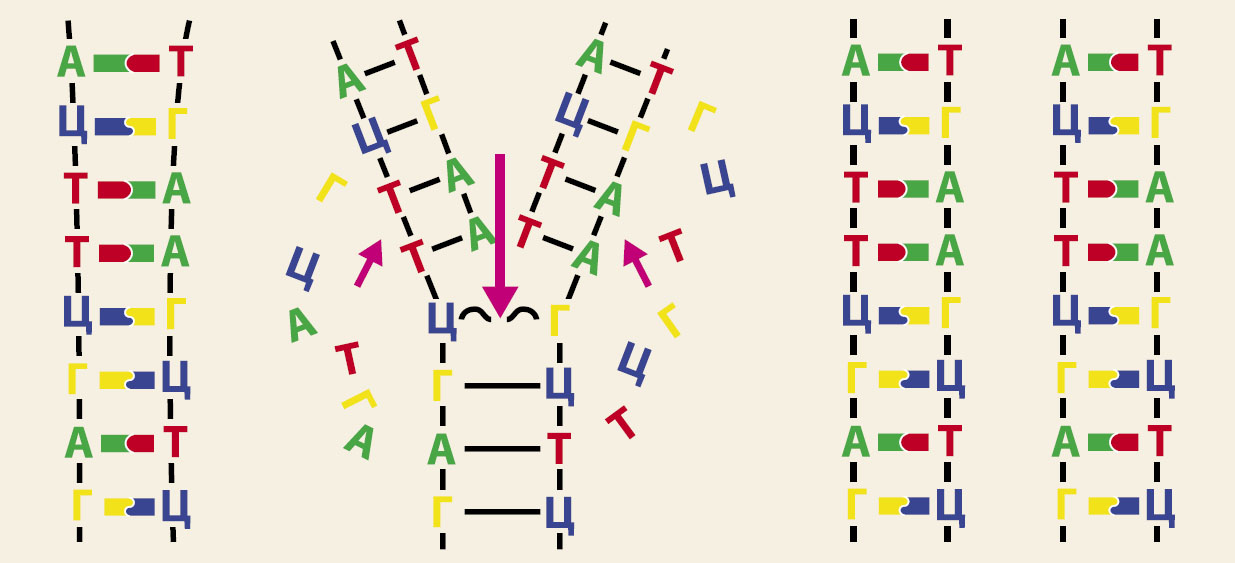
Рис. 1. Так ДНК при делении клетки копирует сама себя
Как и в случае с белками, для чтения ДНК хотелось бы отщеплять по одной или по нескольку «букв» с конца и анализировать, какую же букву мы отделили. Но опять-таки не было способа эффективно это сделать. Зато химики уже умели, имея одну нить ДНК, синтезировать на ней вторую. И гениальная идея Сенгера заключалась в том, что для чтения не надо разрушать — надо строить! Мы будем на одной нити ДНК строить вторую и на разных этапах смотреть, что же мы такое построили.
Итак, берём четыре пробирки. Помещаем в них одну и ту же нить ДНК и строим на ней вторую. Для этого в каждую пробирку подливаем смесь «букв» А, Г, Ц и Т. Но, чтобы останавливать этот процесс на промежуточных стадиях, добавляем туда ещё и немножко изменённые «буквы» — изменённые так, чтобы после них цепочка ДНК уже не могла наращиваться. Изменённую букву А′ добавим в первую пробирку, Г′ — во вторую, Ц′ — в третью, Т′ — в четвёртую.

Первая бумажная распечатка человеческого генома (Лондон, Wellcome Collection)
Что же мы получим? В каждой пробирке будет смесь из недостроенных молекул ДНК. Но в первой пробирке будут все возможные варианты «недостроя», которые кончаются на А (точнее, на А′). Во второй — на Г, в третьей — на Ц, в четвёртой — на Т.
И дальше можно просто разделить получившиеся молекулы и сравнить их длины одновременно по всем четырём пробиркам. Например, если самая длинная молекула получилась в пробирке с А′, следующая по длине — в пробирке с Т′, а две следующие за ней — в пробирке с Ц′, то это значит, что в конце у нас есть последовательность букв ...ЦЦТА. Так мы, двигаясь от самых длинных недостроенных цепей к самым коротким, находим всю последовательность букв. Остаётся только получить исходную последовательность ДНК, везде заменив Г на Ц, а А — на Т (и наоборот).
Молекулы ДНК разделяют по длине с помощью метода, который называется гель-электрофорезом. Длинные молекулы медленнее движутся в электрическом поле (им труднее «протиснуться» через гель), короткие — быстрее. А если пометить конец молекулы светящейся группой или радиоактивным атомом и нанести содержимое четырёх пробирок на четыре разные дорожки, то легко видеть положение разных кусочков ДНК после электрофореза — это будет «лесенка» типа изображённой на рисунке 2.

Рис. 2
Фрагмент молекулы, который здесь проанализирован, имеет последовательность (от конца к началу)
...АТААААААЦТЦАГААЦГГЦТТЦГТА...
А значит, «парная» нить, на которой мы строили этот фрагмент, имеет последовательность
...ТАТТТТТТГАГТЦТТГЦЦГААГЦАТ...
Всё!!!
Конечно, остаются технические сложности. Но в целом метод Сенгера оказался таким эффективным и изящным, что сохранил своё значение до наших дней.
А если нам нужно определить последовательность очень-очень длинного куска ДНК, то и здесь выход есть: нарезаем его на куски особыми ферментами (эти ферменты называются рестриктазами) и каждый кусок анализируем по Сенгеру. Потом, чтобы понять, какой кусок следует за каким, нарезаем другой рестриктазой в других местах и смотрим, как именно наши куски перекрываются. Не так и сложно.
Сейчас амбиции молекулярных биологов велики как никогда (вспомним хотя бы о проекте «Геном человека»), поэтому методы определения последовательностей ДНК постоянно совершенствуются и автоматизируются. Но мы всегда будем помнить, сколь многим нынешние успехи генетики обязаны скромному английскому гению, который «просто возился в лаборатории».

Современный автоматизированный прибор для чтения ДНК
Фото предоставлены автором
* Задумав эту статью, автор предложила своим друзьям задачу: попробуйте составить какую-то осмысленную фразу на русском языке, где было бы всего четыре различные буквы (не считая пробелов и знаков препинания). Достаточно длинной и складной фразы ни у кого не получилось, но были удачные примеры: скажем, «пила пилила-пилила, и липа пала» или «о нет, не тонет енот». Попробуйте и вы! К счастью, словарь природы богаче нашего.











Фредерик Сенгер (1918–2013)